What's New in Incorta Cloud 2024.1.x
Release Highlights
In the 2024.1.x release, Incorta is introducing multiple new features that aim to enhance and ease the user experience:
- Introducing the Incorta Copilot, an OpenAI/ChatGPT integration that brings the power of generative AI to various parts of the platform, including generating dashboard insights using natural language.
- Introducing Incorta Data Studio, a low-code data enrichment tool available as a public preview. With the data Data Studio, users can add, connect, and edit 15+ recipe types and deploy to pySpark materialized views without writing code.
- Introducing a new advanced SQL interface as an alternative to the existing SQL-Interface that is fully Spark SQL compliant, more performant, and provides improved integration with external analytical tools
- A standalone Notebook IDE for data teams as a public preview feature.
- A new Connectors marketplace is now available. With the connectors marketplace, you can install, upgrade, or downgrade connectors without waiting for releases.
- More enhancements to dashboard free-form layouts to help build visually appealing dashboards.
This release uses the Data Agent version 8.2.0. Please download and upgrade to this data agent version using the link in the Cloud Admin Portal.
The 2024.1.1, 2024.1.2, and 2024.1.3 maintenance packs include additional features and enhancements.
Upgrade considerations
Caching mechanism enhancements
The caching mechanism in Analyzer views for dashboards has been enhanced by caching all columns in the view to prevent query inconsistencies. To optimize performance and reduce off-heap memory usage, creating views with only the essential columns used in your dashboards is recommended.
Schema names
Starting with this release, the names of newly created schemas and business schemas are not case-sensitive. Therefore, you cannot create a new schema or business schema that shares the same name with existing schemas or business schemas using different letter cases.
To maintain backward compatibility, the names of existing schemas and business schemas will not be affected.
Lookup function validation
A new validation is now applied to the lookup() function that prevents saving an expression where the result lookup field and primary key field N parameters are not from the same object. As a result, existing expressions with a lookup() function must be updated accordingly; otherwise, these expressions will return #ERROR.
Like function fix
As a result of fixing an issue with the like() function, you must load all tables that use this function from staging.
Custom SQL Connectors
Starting this release, Incorta has changed the directory used for the custom SQL connectors. After upgrading to this release, you must contact Incorta Support to assist you with moving the custom SQL connectors you have configured previously to the appropriate directory. In case of using a Data Agent, you must also copy the custom SQL JDBC driver jars to incorta.dataagent/extensions/connectors/shared-libs/ on the Data Agent host.
New Features
Dashboards, Visualizations, and Analytics
- Dashboard comments collaboration
- Group insights in free-form layout
- Summary Component
- Shapes Components
- Dashboard presentation mode
- Sharing dashboard to Slack and Microsoft Teams
- Null handling enhancements
- Notebook for Analyze Users
Data Management Layer
- Incorta Data Studio
- Connectors marketplace
- Oracle Cloud Applications V2 connector
- GraphQL connector
- Netsuite Searches connector
- OneDrive connector
- Kyuubi connector
- MariaDB connector
- Log-based incremental load
- Incorta Data Delivery enhancements
- Azure Synapse data delivery enhancement
- Date and number format at the view column level
- SQL-compliant verified Business Schema Views
- New Public API endpoints
- New Date functions
Incorta Copilot
- Incorta Copilot Configuration
- Copilot for dashboard
- Copilot for Notebooks
- Copilot for Data Studio
- AI-supported features for business schemas
Architecture and Application Layer
- Enhancements to data load notifications
- Retention of load job tracking data
- Load Plan DAG Viewer enhancements
- Exporting and importing load plans
- Default schema load type at the load plan level
- Load Job Details Viewer enhancements
- Support for merging Parquet segments during loading from staging
- Support for manual load plan execution
- Enhanced the responsiveness of Post-load interruption
- Pause Scheduled Jobs enhancements
- Support OAuth for JDBC connection
- Monitoring the file system usage
- Enhanced performance with parallel snapshot reading
SQLi and Integrations
Features Details
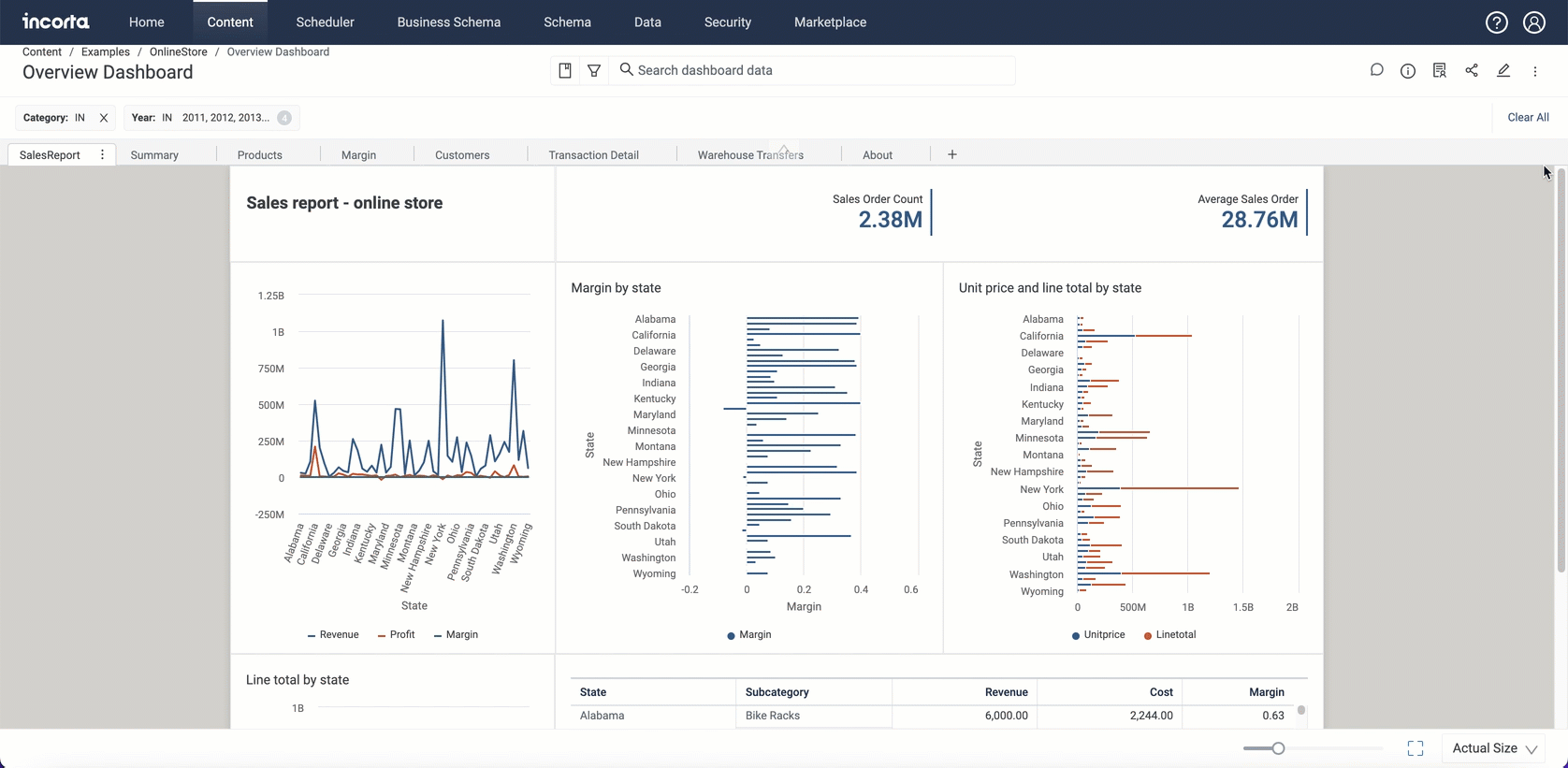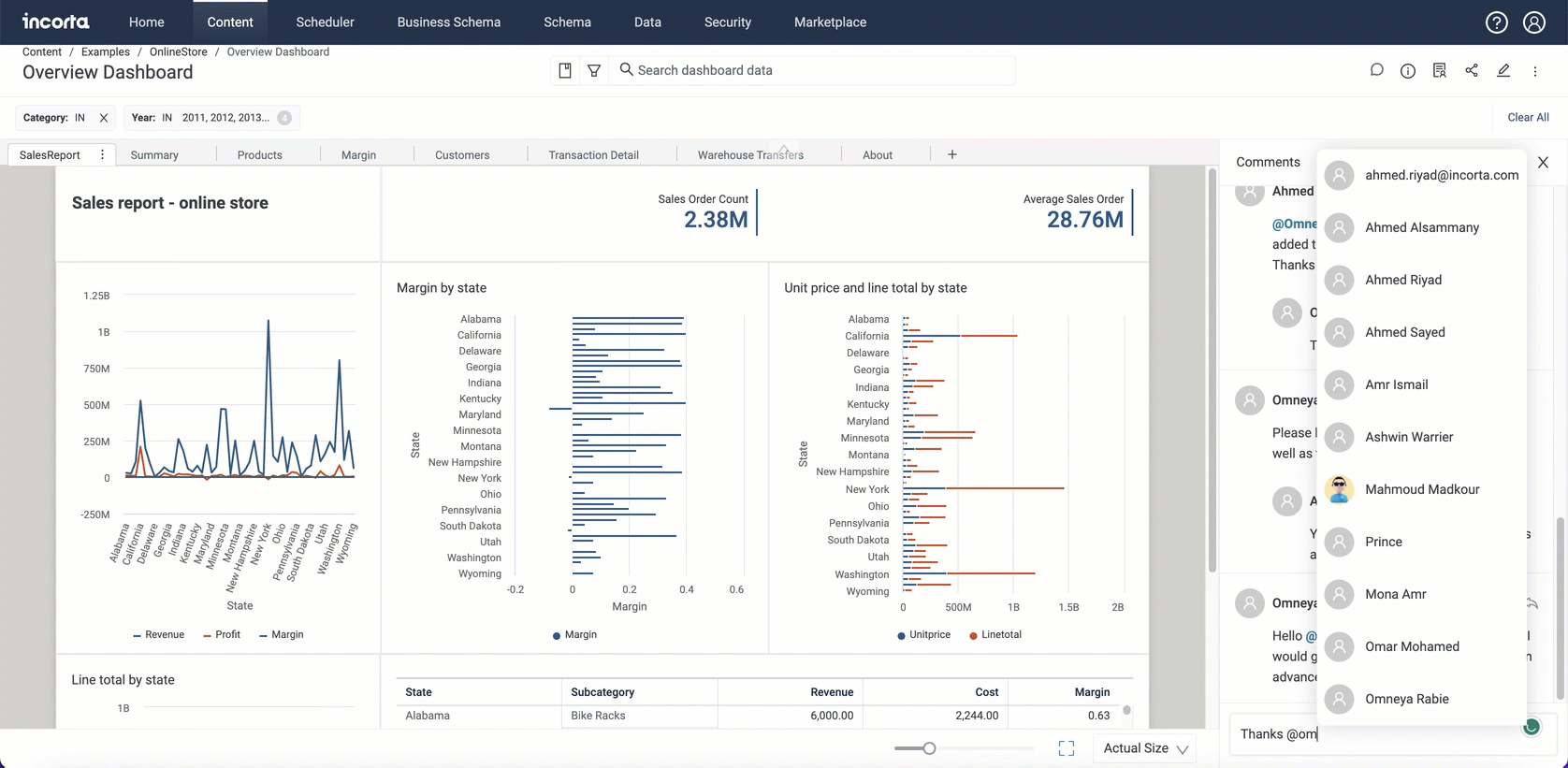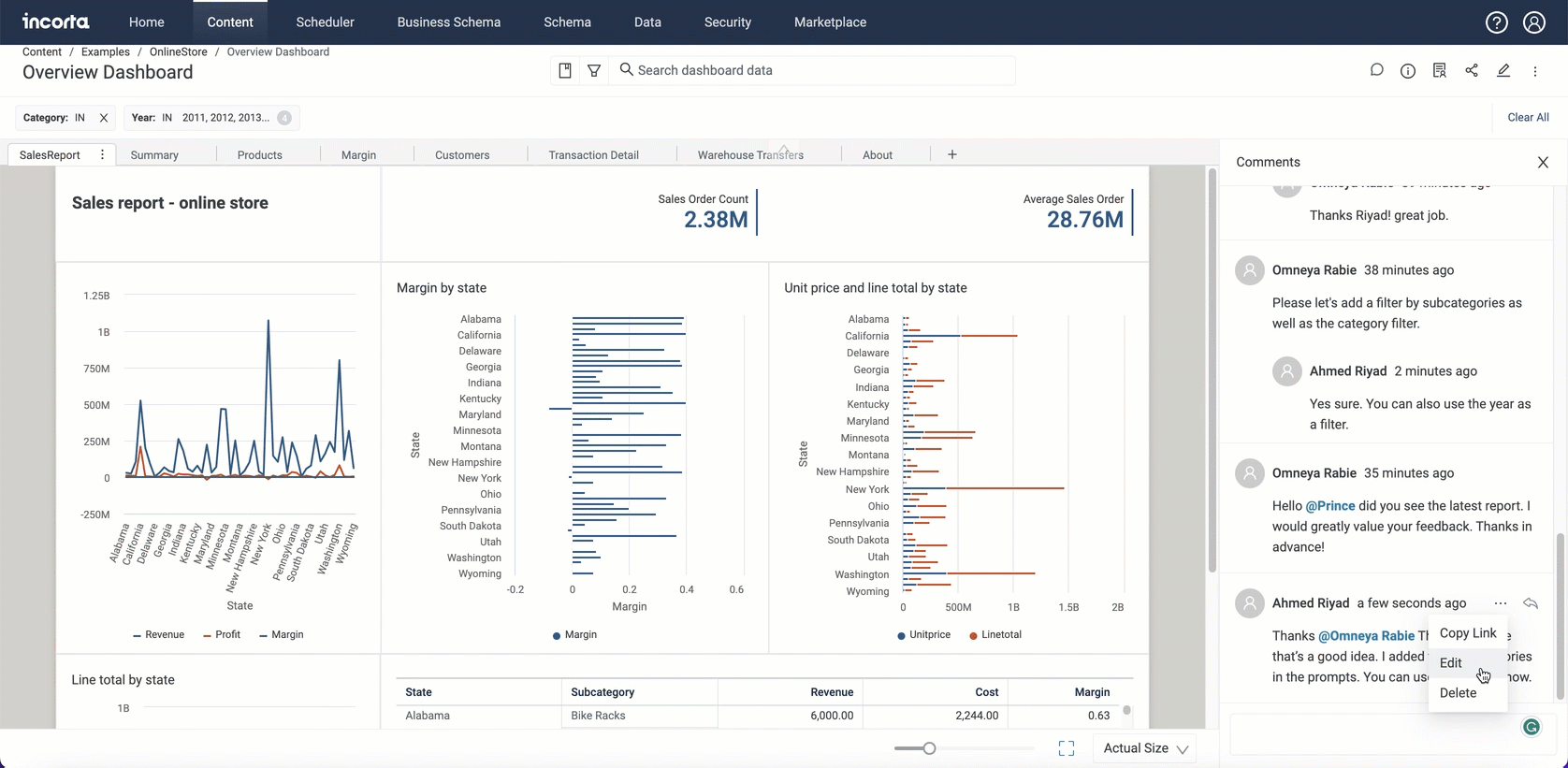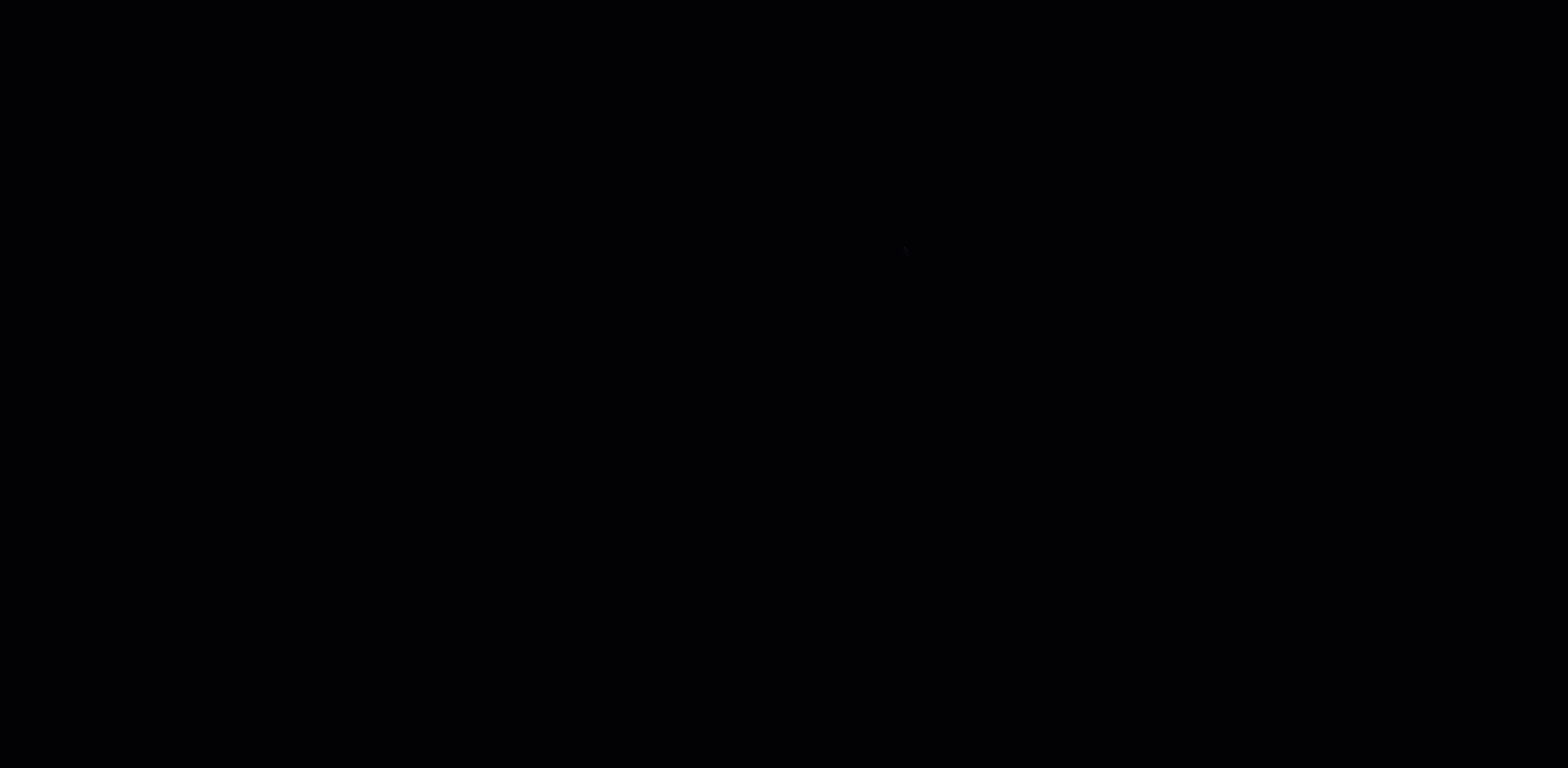
Dashboard comments collaboration
Introducing the new dashboard comments feature, where you can collaborate and communicate with other users by commenting on available dashboards.
Using this feature, you will be able to:
- Post a comment.
- Reply to comment.
- Edit a comment.
- Delete a comment.
- Mention other users.
- Get notified via email in the following cases:
- Another user mentions you in a comment.
- A comment you are mentioned in is edited.
- A reply is posted to a thread you are following.
- Users reply to your comments.
Knowing that the emails contain the following information:
- Who posted the comment.
- Type of comment if it was a mention, a reply, or an edited comment.
- The posted comment/reply.
- The dashboard link.
With the comments collaboration that can occur between multiple users, Incorta still maintains dashboard privacy according to their sharing scheme, which means:
- A user mentioned in a comment but does not have access to the dashboard cannot view the dashboard.
- A user must request access to be able to view the dashboard from the dashboard owner.
- Users with view access to the dashboard can still leave comments.
- Disabled or inactive users’ comments will be visible, where their icons are greyed out.
If a dashboard has comments, Incorta displays the number of comments next to the chat bubble icon.
For more information, refer to Tools → Dashboard Manager.
Group insights in free-form layout
In the free-form layout, you now have the ability to add and organize multiple insights in a group, which enhances the user experience in handling and manipulating these insights. Whether you want to highlight them or relegate them, managing insights becomes more seamless. Additionally, you can effortlessly incorporate new insights into an existing group by simply dragging and dropping them.
You can also do the following:
- Name a group.
- Delete a group.
- Copy a group.
- Ungroup insights.
When dealing with a group, you deal with the insights included within as one entity, which means that selecting one and moving it around within the layout, will move the rest of the insights around as well.
You cannot create a group within a group.
In addition to grouping insights and naming groups, you can rename your insights without editing their titles. You can do this by just double-clicking the insight type name, and typing in a new name, knowing that this action will not affect original insights titles in the dashboard.
For more information, refer to Tools → Dashboard Manager.
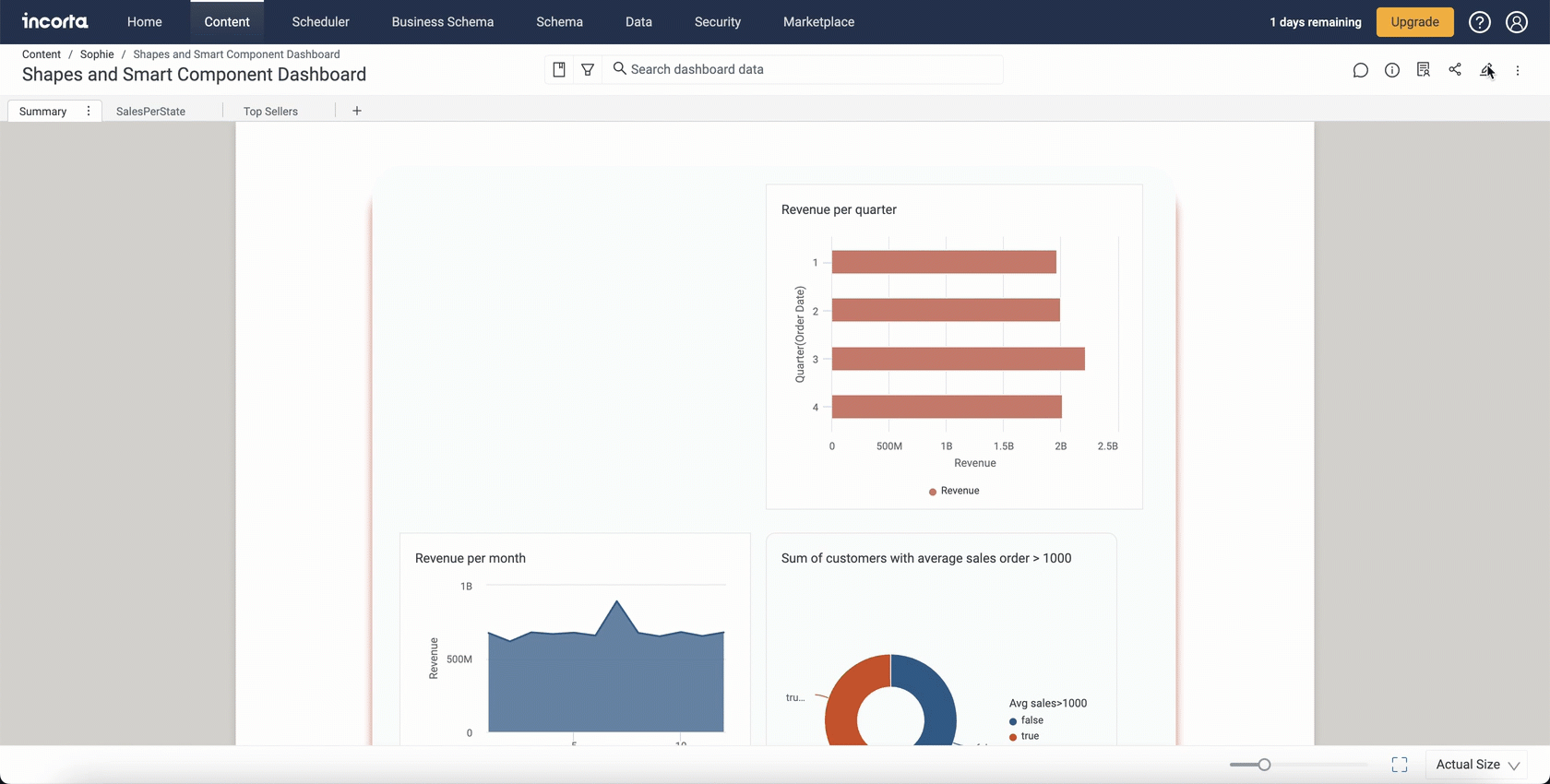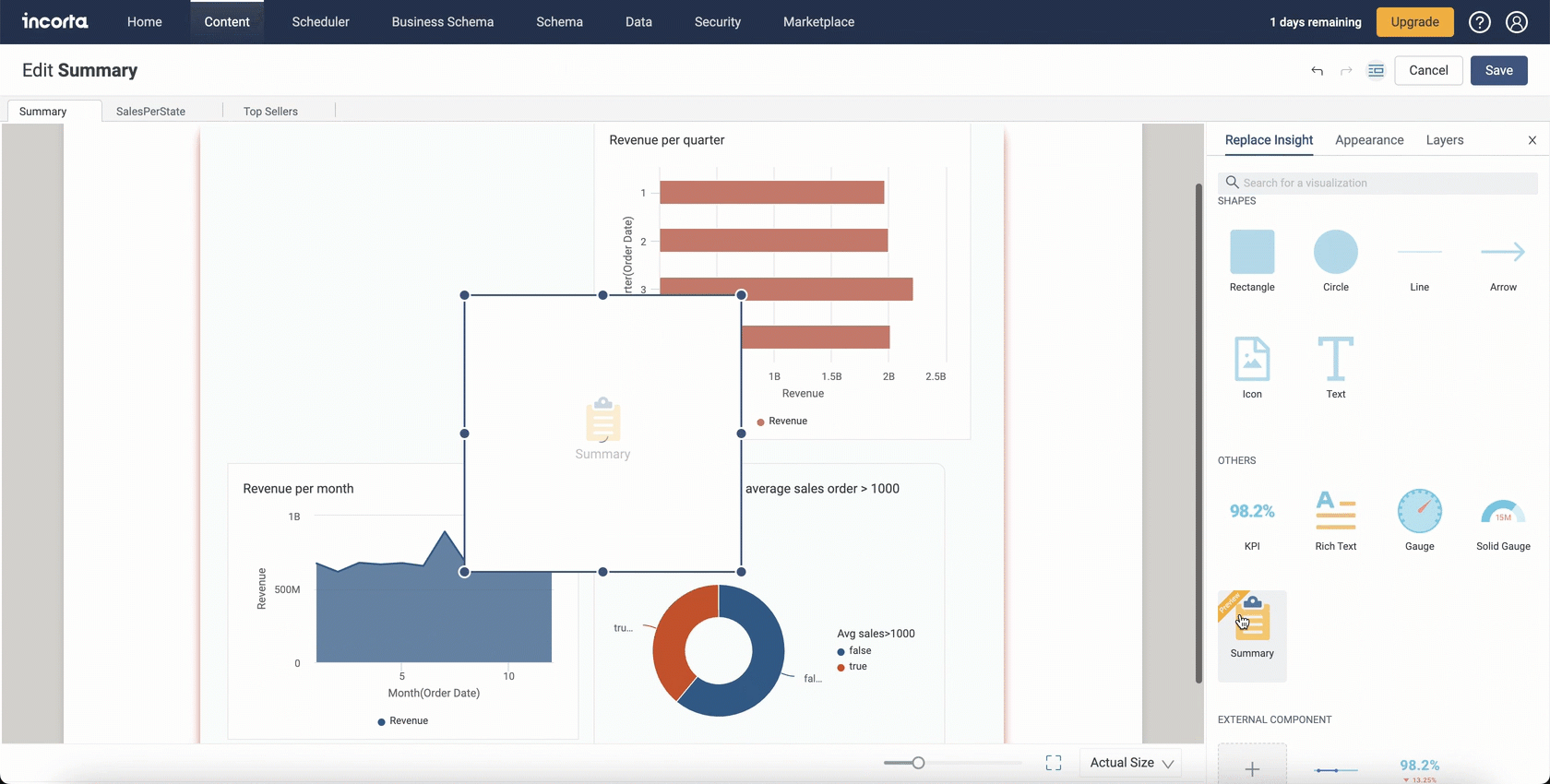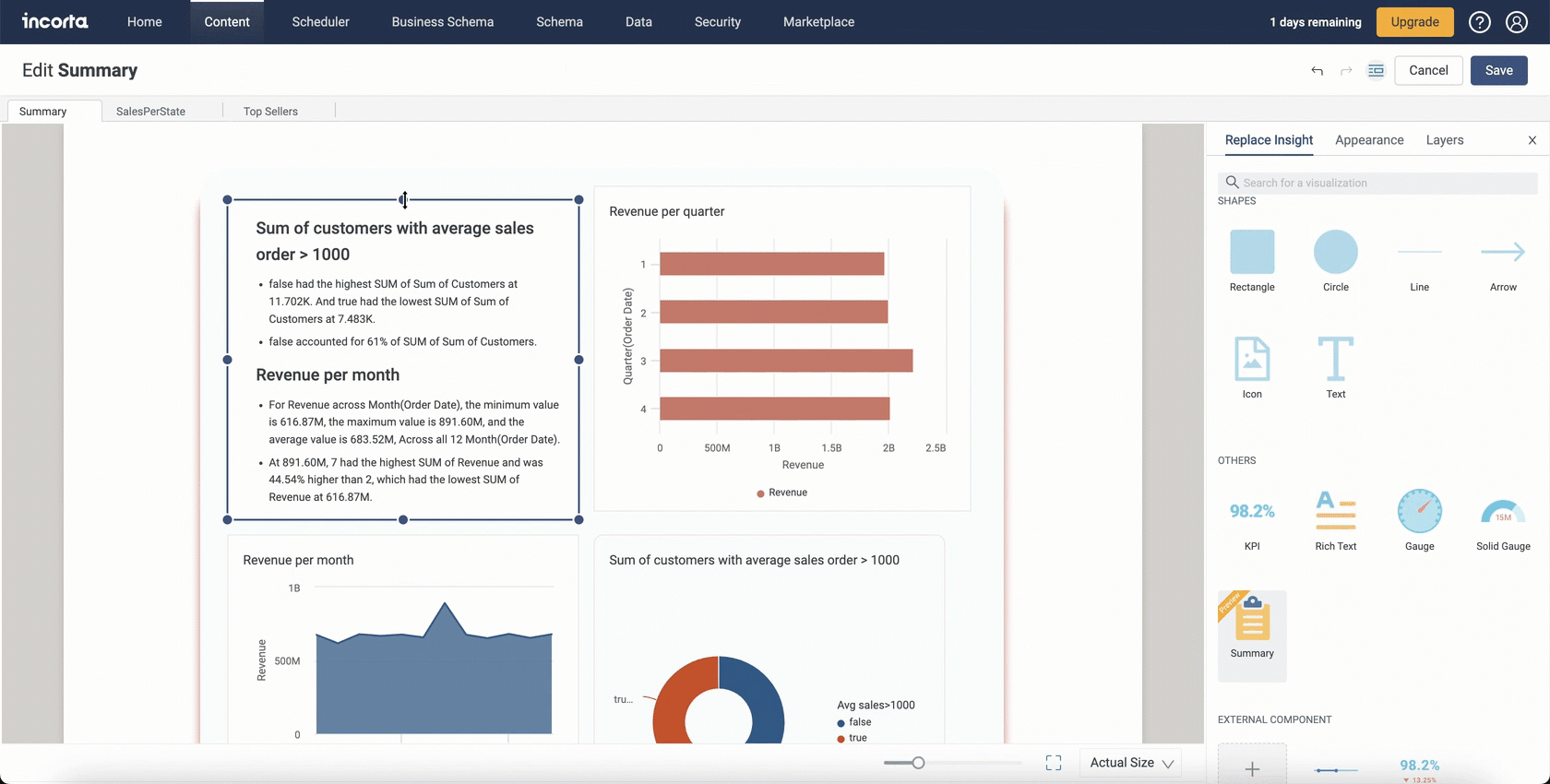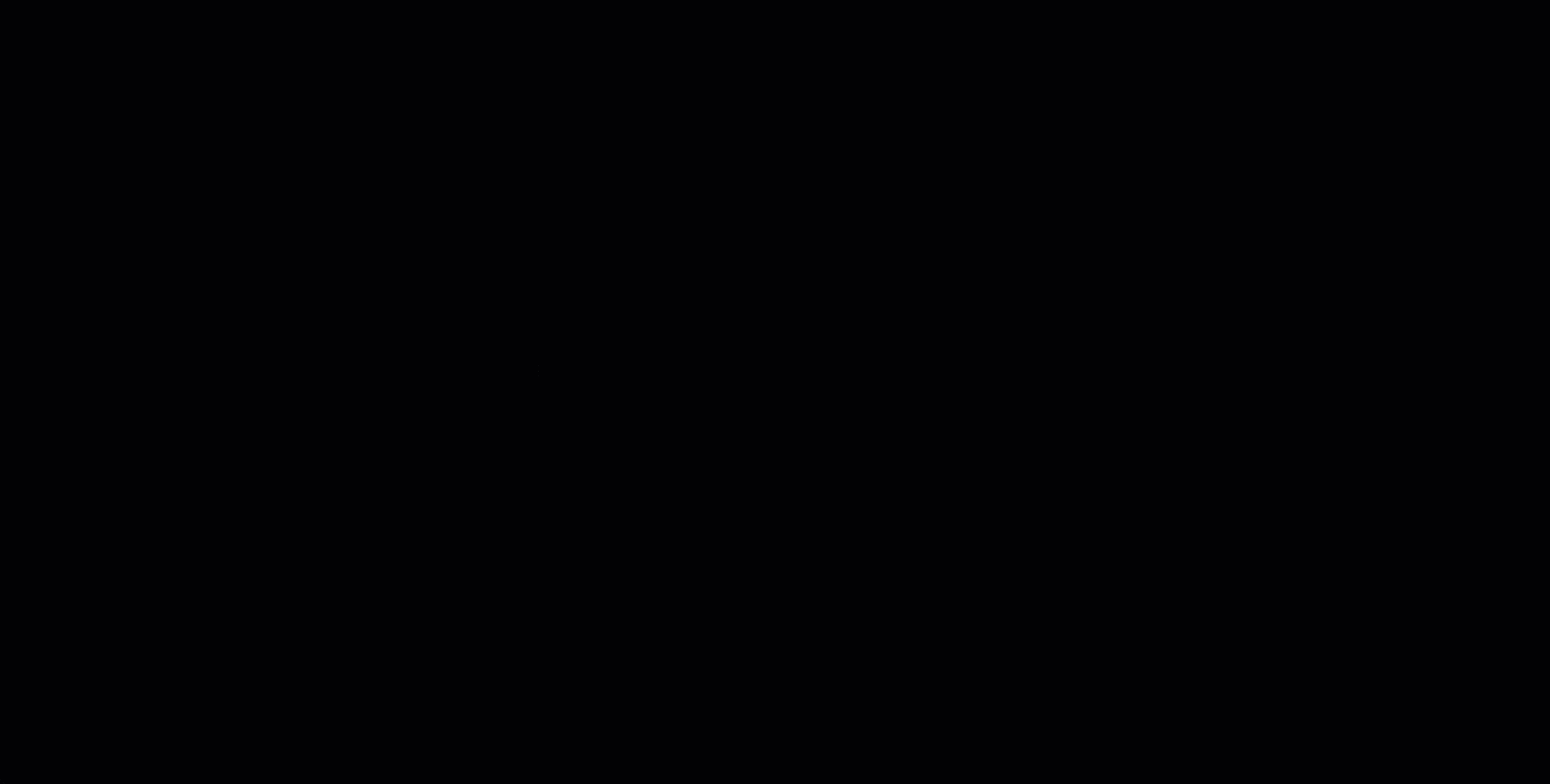
Summary Component
In this release, Incorta is introducing a new smart Summary component that when added to a dashboard tab, it summarizes all insights within this tab.
You can find the Summary component under the Others category in the Add Insight panel.
The Summary component is a native component that does not require any AI integration.
Usually, the Summary component will summarize the available insights in the form of titles and brief bullet points; where each title is equivalent to an insight in the dashboard.
If the insight does not have a title, the component will display the identification number of this component.
For the time being, the Summary component only supports the briefing of the following: Line, Sankey, Scatter, Waterfall, Column, Pie, and Donut visualizations and their variations.
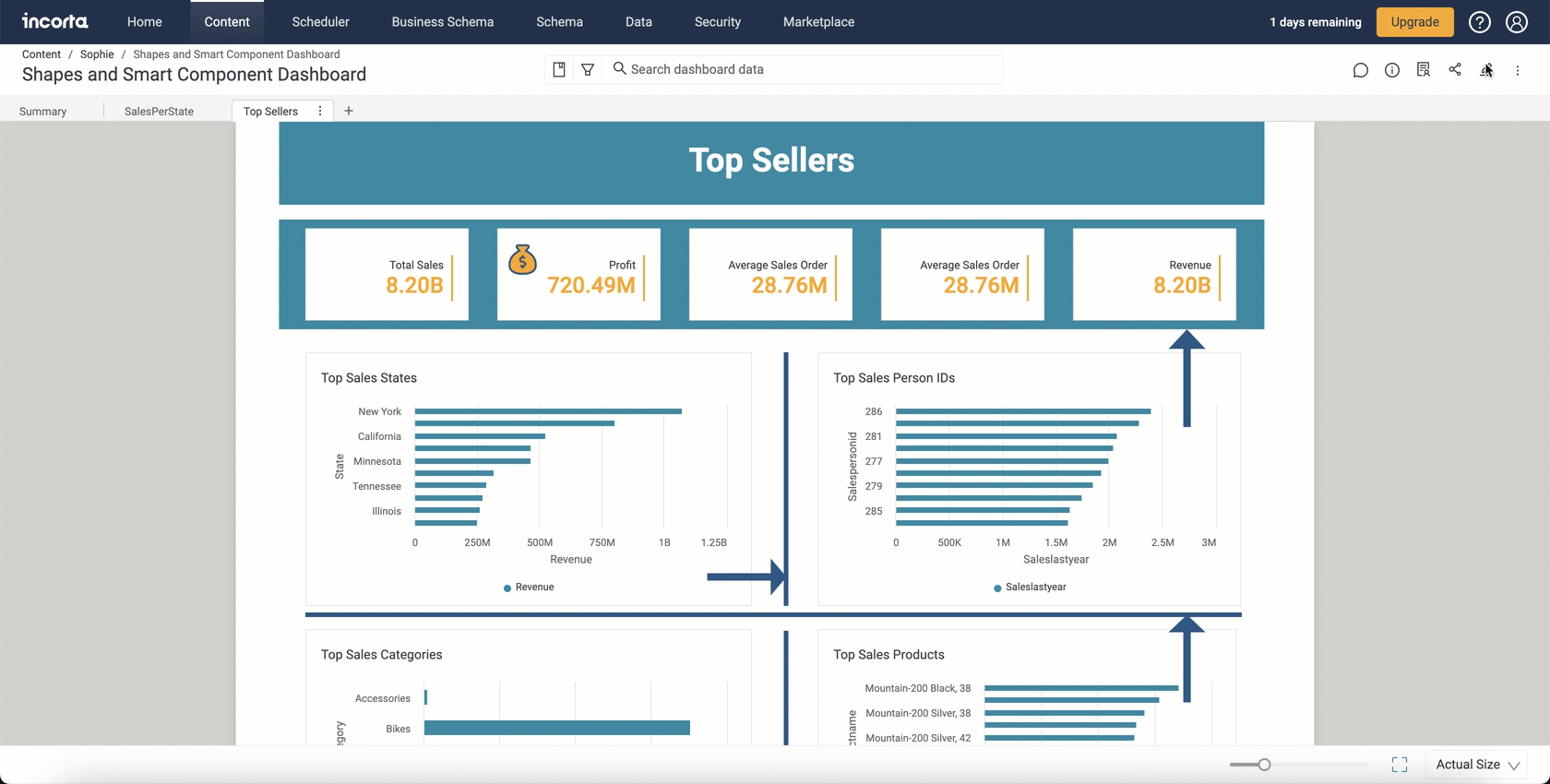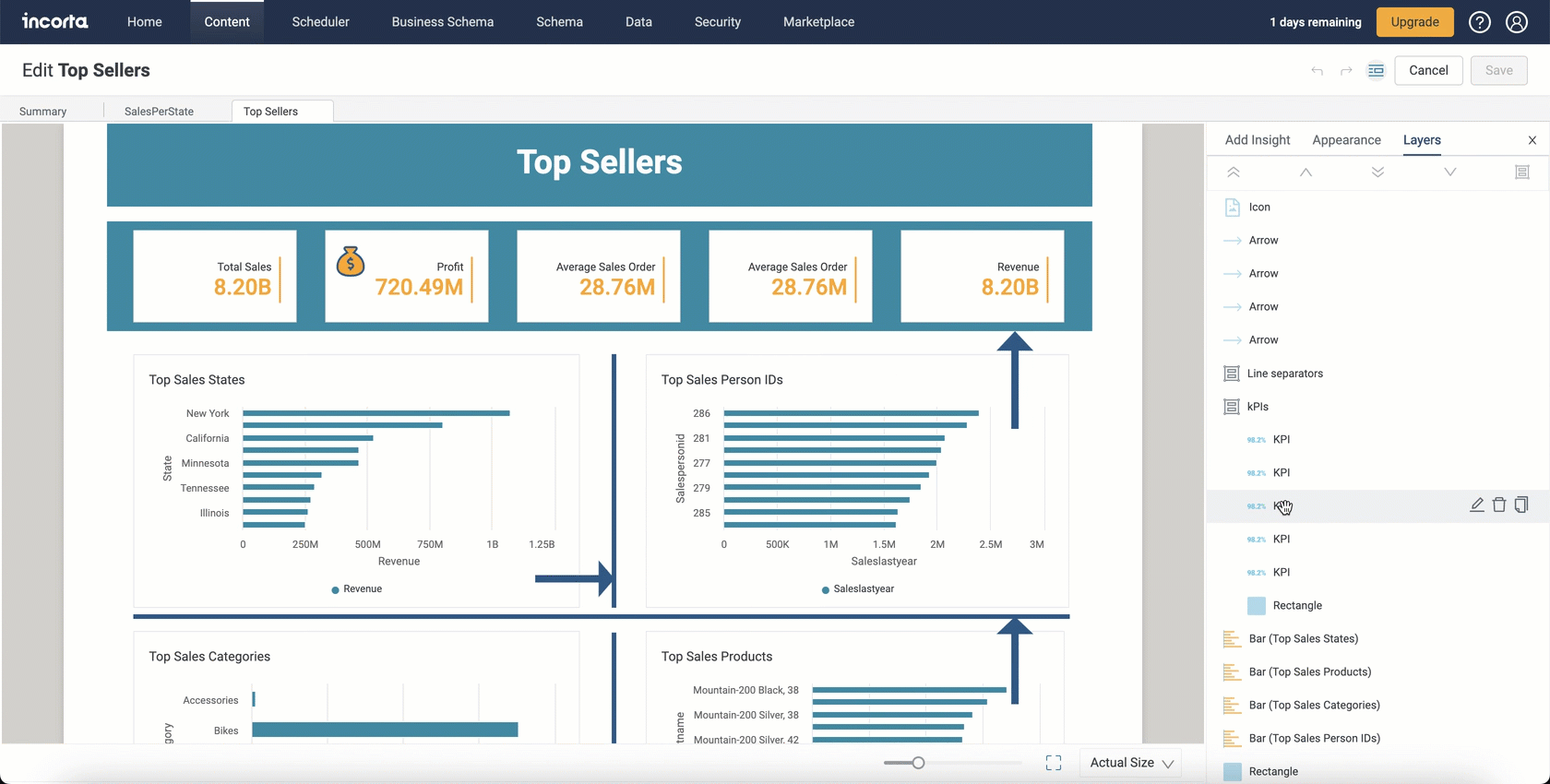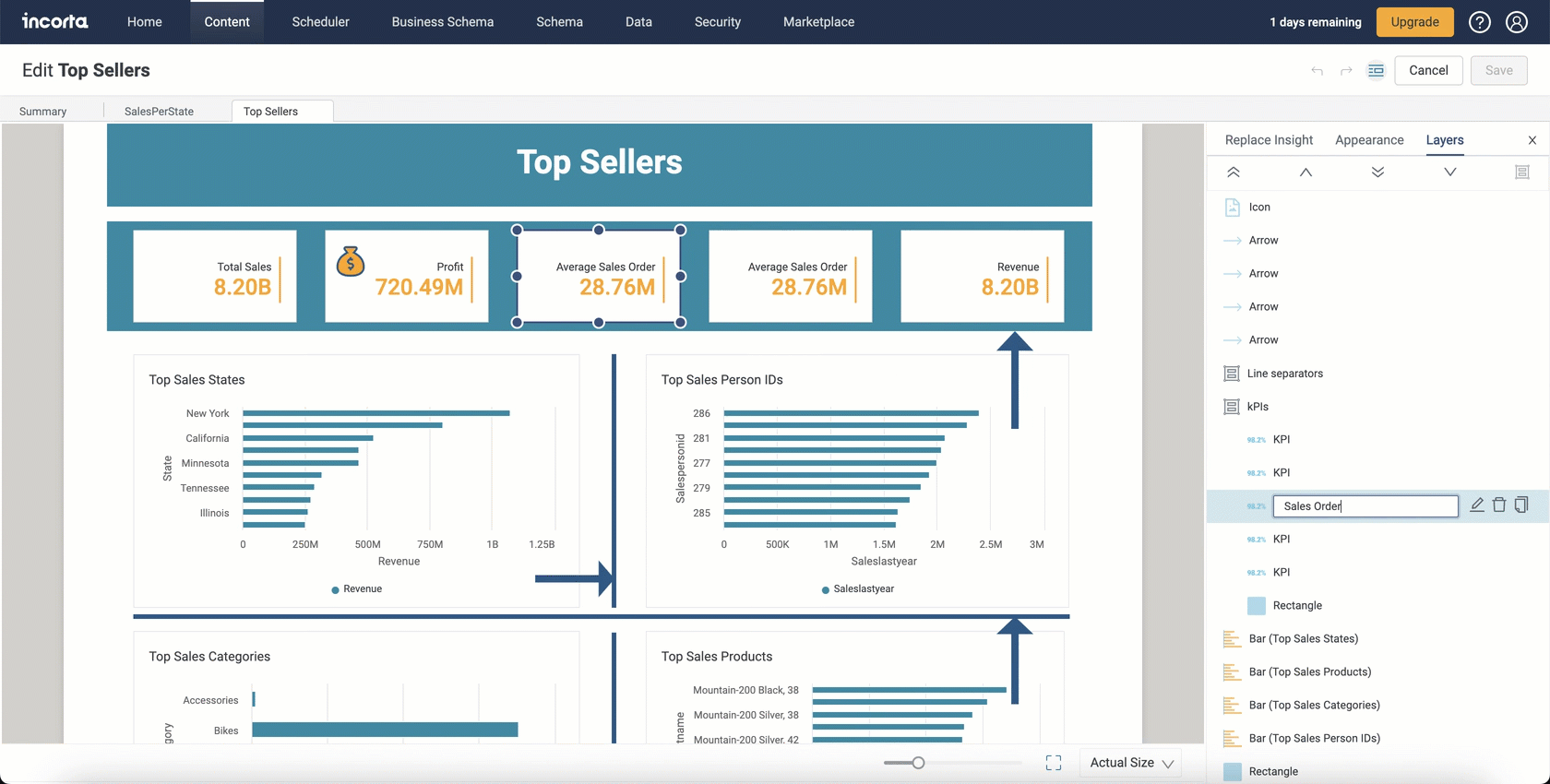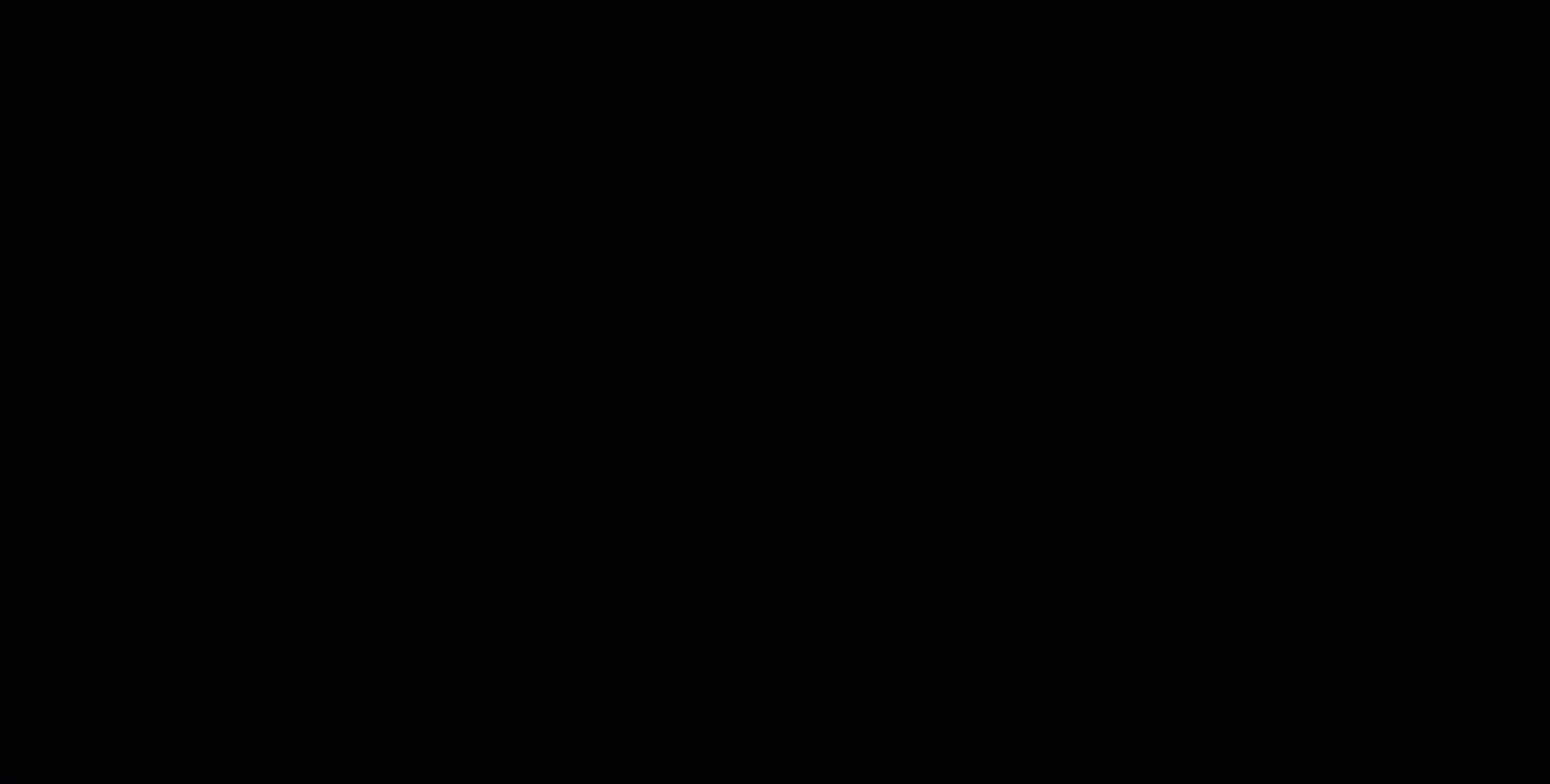
Shapes Components
With the 2024.1.0 release, Incorta is enabling you to elevate dashboard designs with the new shapes and icons feature.
You can now integrate lines as delimiters between insights, creating a clear and organized visual hierarchy. Use rectangles strategically to differentiate between various insights.
With this addition, you can incorporate lines, arrows, rectangles, circles, and a variety of other shapes and icons into your dashboard creations.
You can also embed text within your added shapes, resize them, add shadows, and change icon styles.
You can find the new Shapes category in the Add Insight panel with the following available:
- Rectangle
- Circle
- Line
- Arrow
- Icon
- Text
Under Appearance, you can customize the appearance of the shapes using various settings and controls, such as shadows and text.
For more information, refer to Visualizations → Shapes.
Dashboard Presentation Mode
Now you can present your dashboard directly through the new dashboard presentation mode introduced in this release. A new presentation icon is added in the action bar in the Dashboard Manager that enables you to show your dashboard tabs in fullscreen mode.
When selecting the Presentation icon, Incorta displays the currently selected tab in full screen.
During the presentation, you can switch between tabs using the available arrow icons and keyboard arrows; or simply select the Play button in the Control bar.
Using the Control bar, you can also adjust the displaying time for each tab, as well as choose how to fit the content of your tab within the screen.
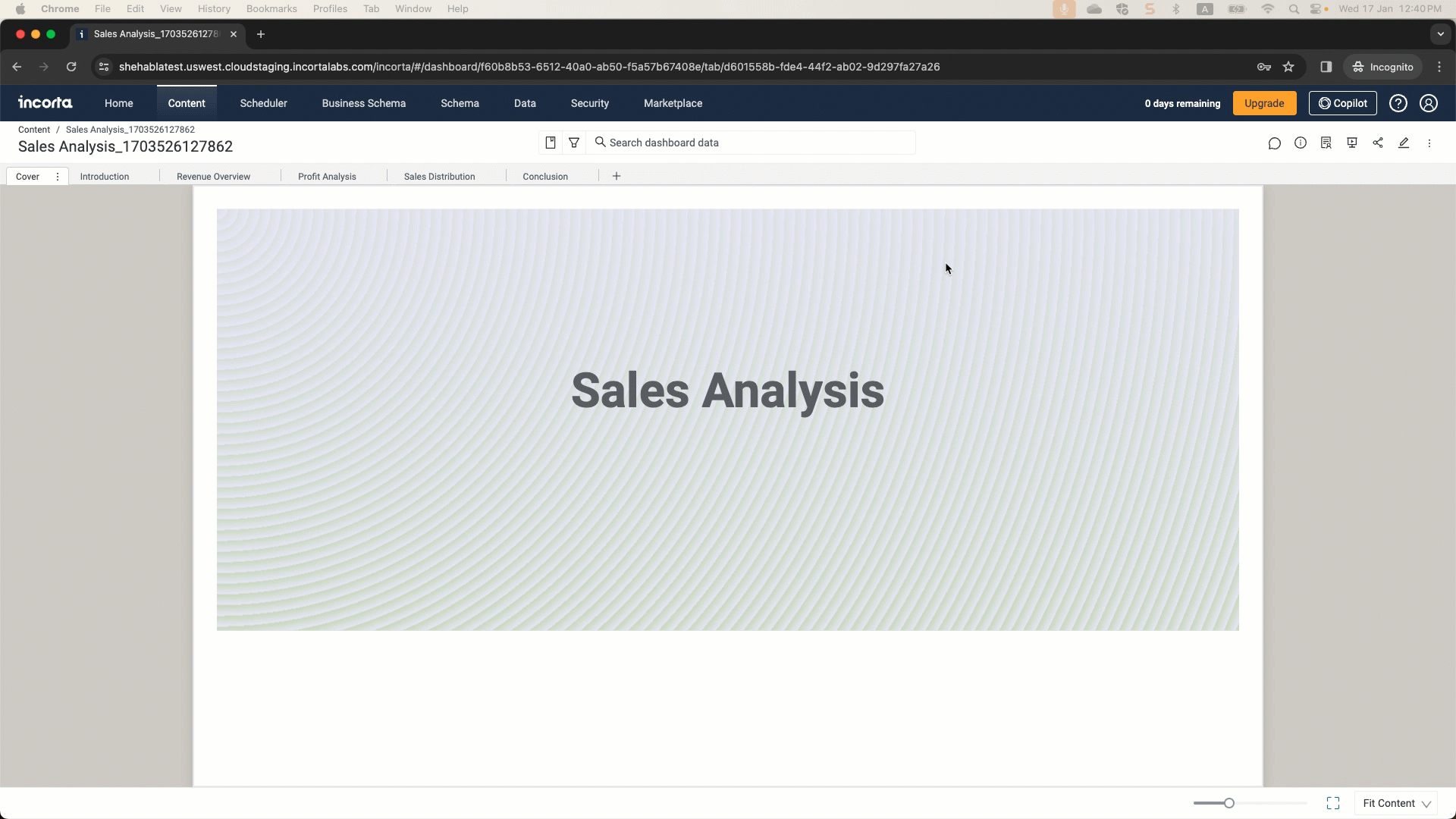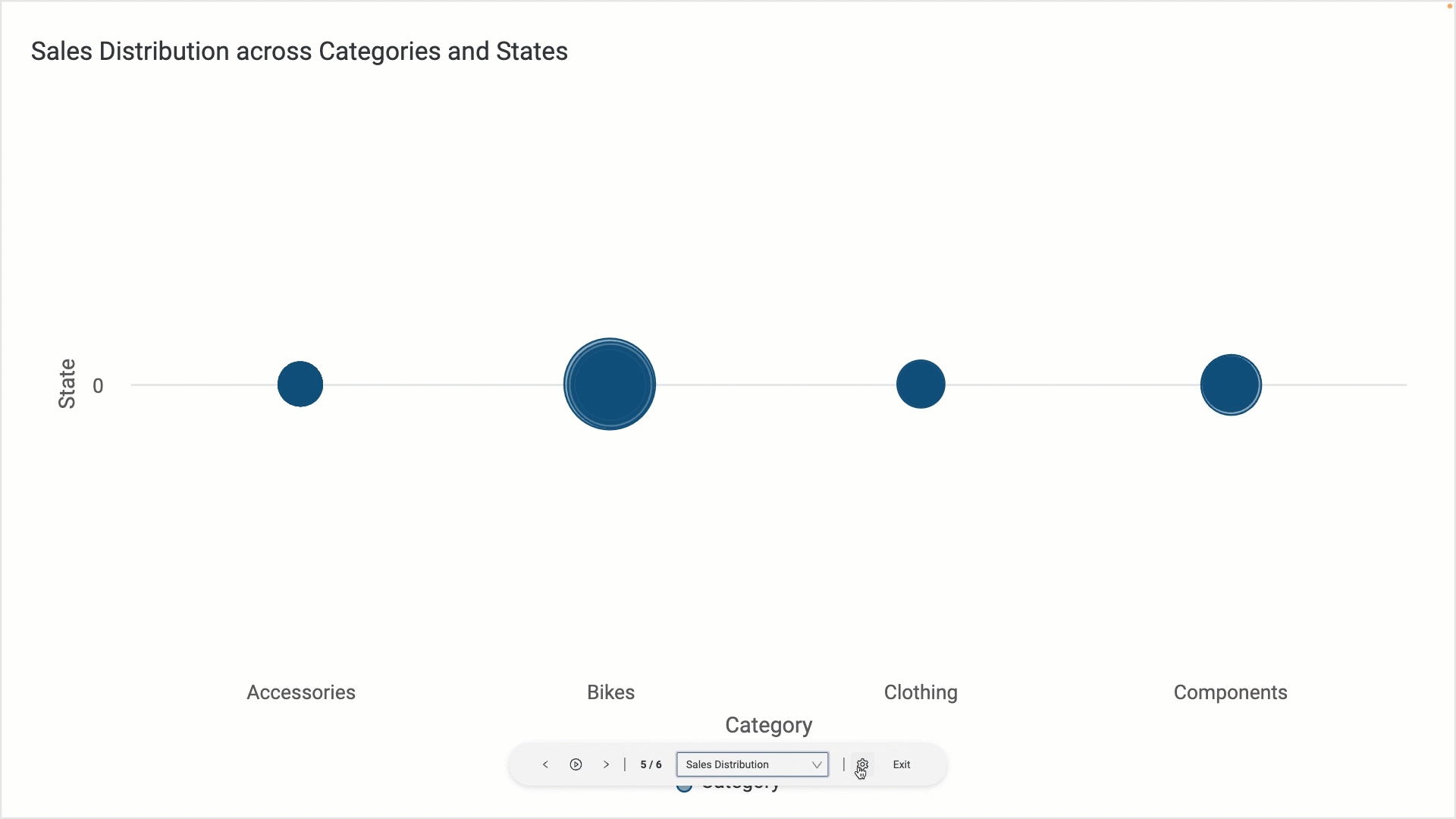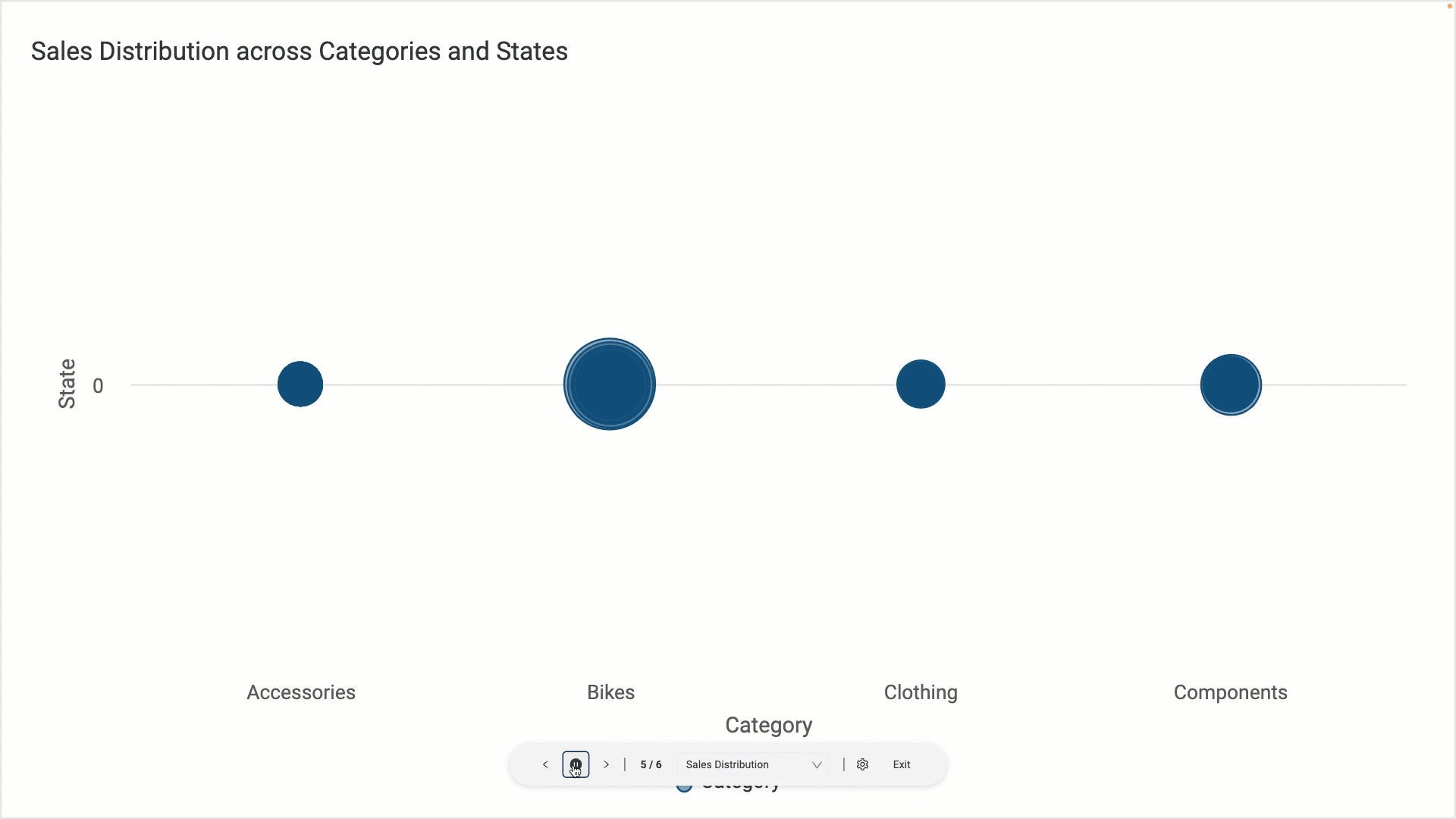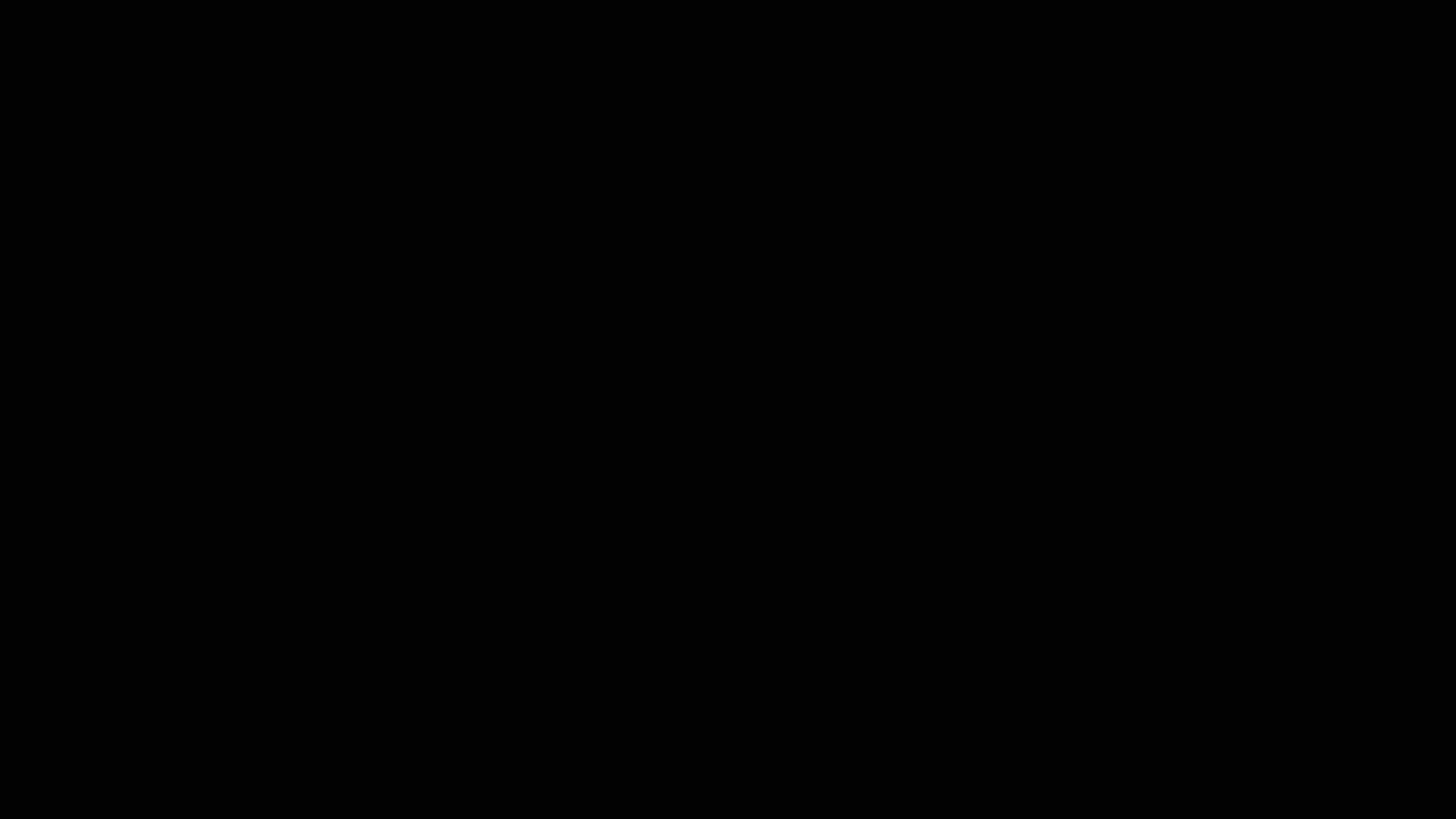
For more information, refer to Tools → Dashboard Manager.
Sharing dashboard to Slack and Microsoft Teams
In this release, Incorta is enabling you to send dashboards using messages to Slack and Microsoft Teams (MS Teams). You can send dashboards to both private and public channels.
As a CMC admin, you must first configure Slack, MS Teams, or both to enable Incorta users to share dashboards using these communication platforms.
If you enable or disable the integrations while having Analytics open, you must ask your users to refresh the browser for the change to take effect.

After configuring either Slack or MS Teams, do the following to send or schedule a dashboard:
- Log in to Incorta Analytics.
- Select your dashboard.
- Select the Share icon from the Action Bar, then Send/Schedule a Report.
- Select Communication Platform as your sharing option.
| For MS Teams | For Slack |
|---|---|
● Select the Platform as Microsoft Teams ● For the first time, you use this option: 1. Enter a Channel Name. 2. Paste the webhook URL you configured for this channel. 3. Select whether to show it to all users or just yourself. 4. Select Add Channel. ● For already existing channels, select the needed channel. | ● Select the platform as Slack. ● Select the channel you want to send the report to, knowing that: 1. Incorta lists all public channels in your Slack workspace whether you have invited the bot or not, so you must make sure you have invited the bot to be able to send the report. 2. For private channels, Incorta only displays private channels that have the bot invited. ● (Optionally)Enter the file name and select its format. ● Choose whether to append a timestamp to the file name. |
- (Optionally) Enter a message to associate with the shared dashboard.
- Select Done.
For now, Incorta supports only sharing dashboard URL to Microsoft Teams; while it supports the following formats to share to Slack:
- CSV
- XLSX
You can also search the available channels using a channel name.
For more information, refer to Slack Integration and Microsoft Teams Integration documents.
If you enable or disable the integrations while having Analytics open, you must ask your users to refresh the browser for the change to take effect.
Null handling enhancements
The Analytics Service has extended its support for null value handling in the following areas:
- Functions:
- Arithmetic Functions
- Boolean Functions
- Conversion Functions
- Date Functions
- Miscellaneous Functions
- Analytics Functions
- Filtering data based on formula columns.
- Sorting based on formula columns.
- Formulas involving logical and comparison operators.
- Arithmetic operations.
This expansion of support for null value handling in these areas signifies an important improvement in the capabilities of the Analytics Service, allowing for more comprehensive and accurate data analysis and manipulation.
The Null Handling option has been moved to CMC > Server Configurations > Incorta Labs.

For more information, refer to References → Null Handling.
Notebook for Analyze Users
Starting this release, Incorta is introducing the Notebook for users with Analyze Users user role can use the notebook within the Content Manager. The Notebook for Analyze Users only supports verified Views.
Currently, the Notebook for Analyze Users is a preview feature. To enable it on your cluster, you need to contact Incorta Support. Knowing that enabling Notebook for Analyze Users will automatically enable the Advanced SQL Interface and hence Null Handling.
The following languages are supported:
- Spark SQL
- PySpark
- Scala
- SparkR
Prerequisites
- The cluster must have Spark 3.3.0 or higher.
- You must enable the Notebook Integration toggle from the CMC or cloud admin portal under Default Tenant Configurations > Incorta Labs.
Known limitations
- You cannot create or import Notebooks in folders.
- Sharing Notebooks is currently not available.
- Only 10 concurrent connections are allowed per cluster to create Notebooks simultaneously. Knowing that if a user has two open tabs for Notebook, it is considered two different sessions.
For more information, refer to Tools → Content Manager.
Incorta Data Studio
Incorta is adding the new Data Studio tool to its bundle this release. Data Studio is a powerful tool that enables users with minimal technical expertise to create Materialized Views (MVs) using a simple graphical interface.
An Incorta Labs feature is experimental, and functionality may produce unexpected results. For this reason, an Incorta Lab feature is not ready for use in a production environment. Incorta Support will investigate issues with an Incorta Labs feature. In a future release, an Incorta Lab feature may be either promoted to a product feature ready for use in a production environment or be deprecated without notice.
Using the Data Studio, schema managers can perform multiple actions and transformations on your data using sequential steps and recipes. As recipes are added to the canvas, the corresponding pySpark is generated automatically. When the code is ready to be saved, use the Save MV recipe to push the code into a schema.
The Data Studio is available in this release as a trial version.
There are multiple recipes available, in addition, you can create your own recipe. The following table briefly explains the available recipes:
- Filter – Filter data based on a condition.
- Fuzzy Join – Match similar words together based on another reference that can be a table or file.
- Change Type – Change the data type of one or more columns within a table.
- Code – Simply create a recipe by writing your own code or using the Incorta Copilot to generate code on your behalf.
- Select Columns – Include or exclude columns from a table or another recipe.
- Join – Join two tables or recipe output, choosing between different types of joins.
- Data Quality – Check the data compliance against various rules that you define.
- Union – Combine two tables that have the same number of columns together.
- Unpivot – Change columns into rows and vice versa.
- Sort – Sort a table in ascending or descending order.
- New Column – Add a new column to your table by writing a formula, or using Copilot to write it on your behalf.
- Sample – Retrieve sample data from the table with a specified fraction.
- Group – Create an aggregated view of your data with granularity defined by grouping.
- Rename Column – Rename columns of the table.
- Split – Split a table using a specified ratio.
- SQL – Write your own SQL statement or with the assistance of the Copilot.
- Save MV – Save the pySpark generated by the series of recipes into a pySpark materialized view. The materialized view should be loaded from the schema
Known Limitations
- Any change in the MV from a physical schema will not reflect in Data Studio.
- While using a certain schema, Incorta locks that schema preventing any updates.
- Users who do not have access to schemas will have view-only access to data flows where these schemas are used.
- Deleting users will subsequently delete any data flows they have created.
- Data Studio performance may degrade when using large tables with many columns.
- Data flows can not be exported or imported.
Connectors marketplace
Incorta is introducing the new Connectors marketplace to cloud users. With the new marketplace, you can install, upgrade, and downgrade your connector version independently from any Incorta releases.
You must contact Incorta Support to assist you with moving any custom connectors you have configured previously to the appropriate directory.
You must contact your CMC administrator to enable CData connectors so you can install them.
In the marketplace, the connectors are categorized according to their type and functionality. The connectors are displayed as cards within the marketplace, each card contains the following information:
- Connector name
- Connector version
- Connector category
- Green tag if it is installed
- Yellow tag if it is new or has an available update

On a connector details page, you can view a brief description of the connector, a link to the connector’s full documentation, and a list of available updates (if they exist).
For fresh installations, the following connectors are installed by default:
- MySQL
- Oracle
- Microsoft SQL Server
- Custom Cdata
- Custom SQL
- Local Files
For upgrades from previous versions, connectors that you are using with physical schemas will exist, in addition to the above connectors. You can download any other connector that you might need from the Marketplace.
For more information, refer to References → Connectors.
Oracle Cloud Applications V2 connector
Incorta is introducing a new enhanced and improved version of the Oracle Cloud Application connector, where you can control who triggers the BICC jobs (BICC or Incorta) and avoid any synchronization issues that may occur.
In addition, you can control the list of the BICC jobs that you need to run by defining it in the connector. You can add the BICC IDs in a list separated by a comma, space, or a new line.

For more information, refer to Connectors → Oracle Cloud Applications V2.
GraphQL connector
Incorta is introducing the new GraphQL connector in this release. GraphQL is a query language for APIs and a runtime for fulfilling queries with existing data. The GraphQL connector uses the cdata.jdbc.graphql.jar driver to connect to a GraphQL resource and get data.
The GraphQL connector is a preview connector.

For more information, refer to Connectors → GraphQL.
NetSuite Searches connector
Incorta added a new connector for NetSuite Saved Searches in this release. NetSuite enables users to search for any record type in the system and save this search in the form of a Saved Search. Incorta connects to retrieve this data to be able to process it and build insights.
The NetSuite Searches connector is a preview connector.

For more information, refer to Connectors → NetSuite Searches.
OneDrive connector
The OneDrive connectors enable you to connect to your Microsoft OneDrive. The OneDrive cloud service connects you to all your files stored in the cloud. It lets you store and protect your files, share them with others, and get to them from anywhere on all your devices.
The OneDrive connector is a preview connector.

For more information refer to Connectors → Microsoft OneDrive.
Kyuubi connector
The new connector is a JDBC connector that enables you to connect to Apache Kyuubi. Apache Kyuubi is a distributed and multi-tenant gateway to provide serverless SQL on Data Warehouses and Lakehouses. Kyuubi builds distributed SQL query engines on top of various kinds of modern computing frameworks.
The Kyuubi connector is a preview connector.

For more information refer to Connectors → Kyuubi.
MariaDB connector
In this release, Incorta is introducing the new MariaDB connector. MariaDB is one of the popular open-source relational databases. It is also the default database in most Linux distributions.
The MariaDB connector is a preview connector.

For more information refer to Connectors → MariaDB.
Log-based Incremental Load
Incorta is now supporting log-based incremental load using the change data capture (CDC).
CDC is the process of identifying and capturing changes made to data in a database using logs and then delivering those changes in real time to a downstream process or system.
Currently, the log-based incremental load is a preview feature.
Prerequisites
To be able to use the log-based incremental load, you need to be aware of and apply the following:
- Install and configure Apache Kafka and Kafka Connect.
- Configure Debezium connector, knowing that Incorta recommends using Debezium version 2.4.1.
- Disable snapshot while configuring Debezium.
- Make sure Debezium connector is configured to send data types to Incorta by adding the propagate property.
- Log-based incremental load only supports database physical tables.
- Tables must have primary keys.
The log-based incremental load is currently supported for the following SQL-based connectors:
- MySQL
- Microsoft SQL Server
- Oracle
- PostgreSQL
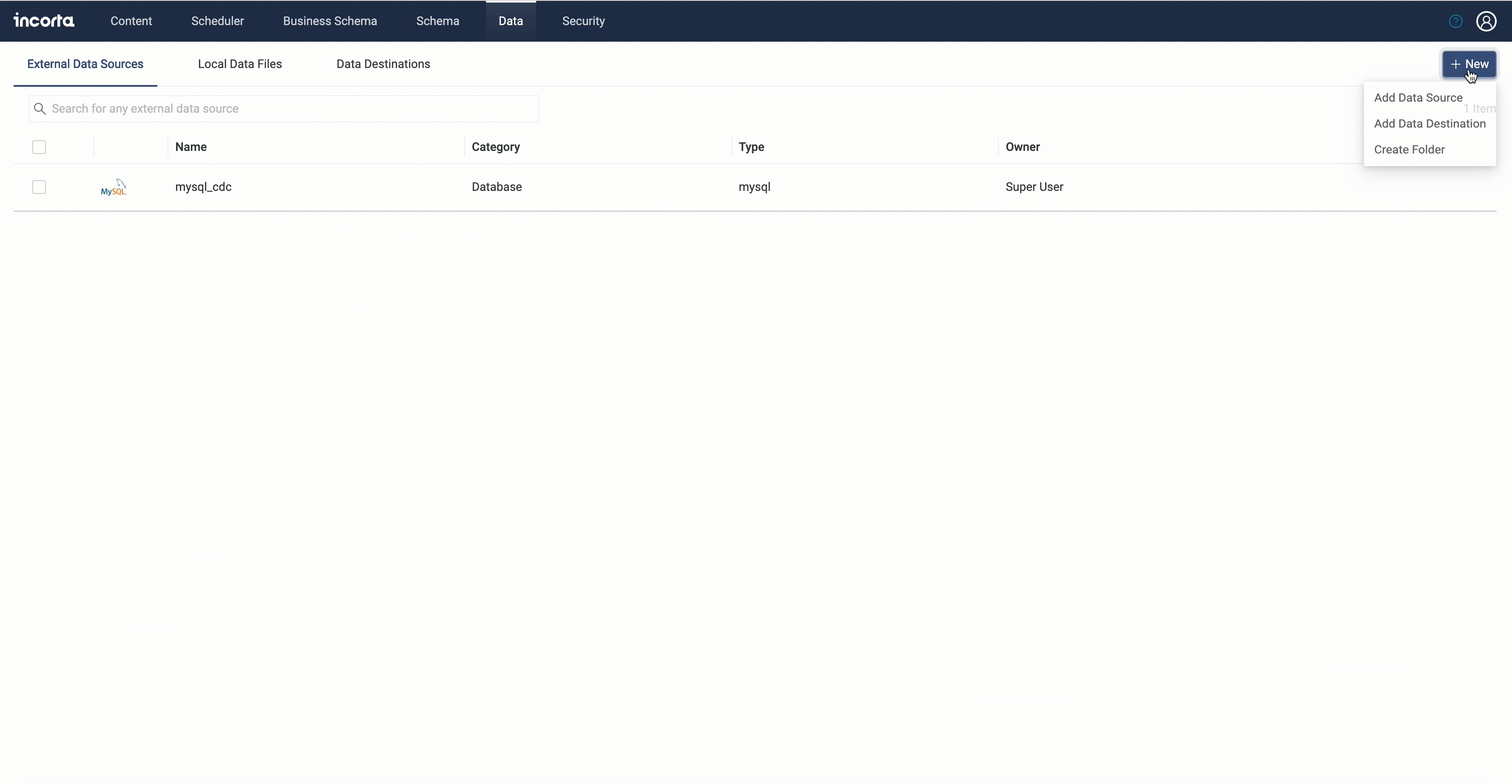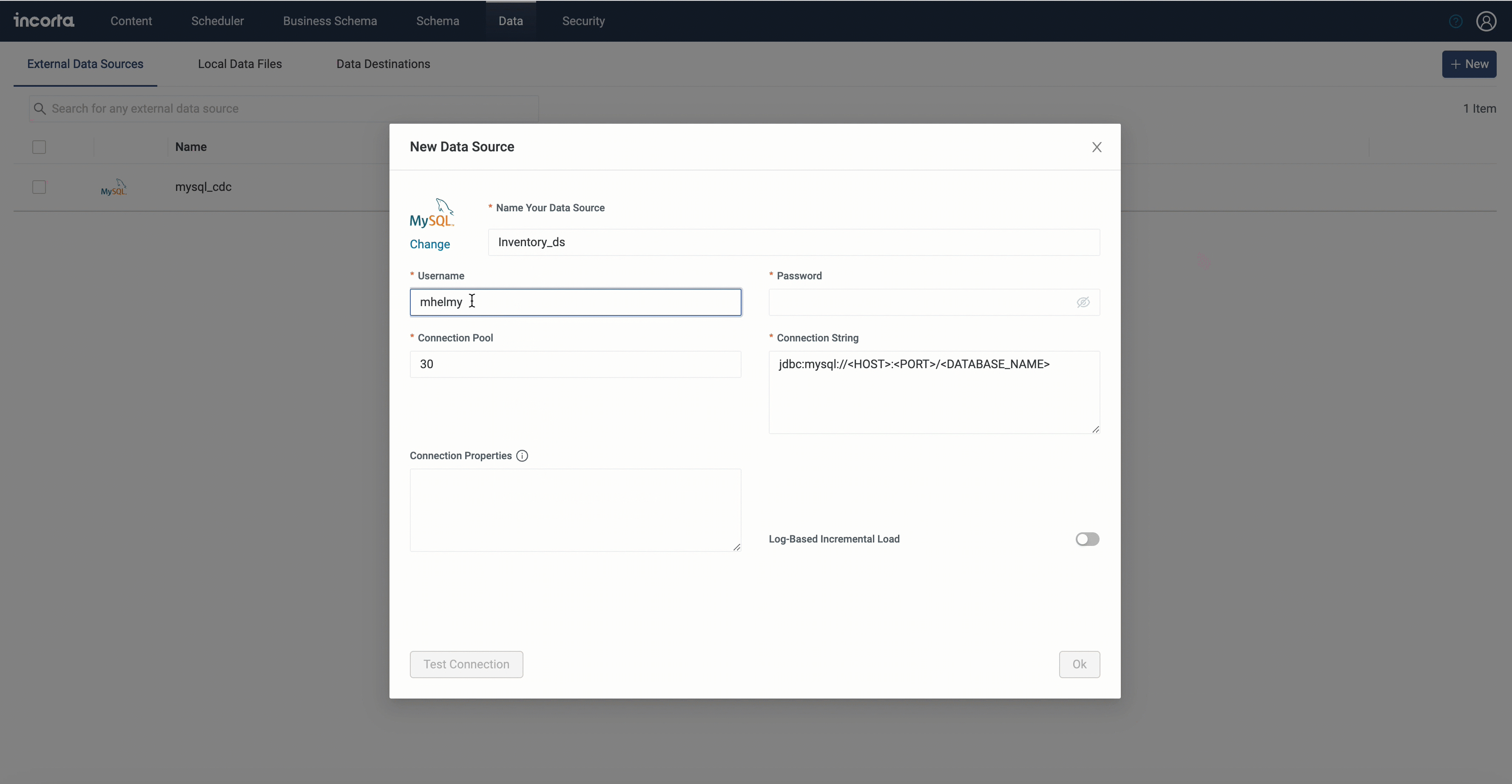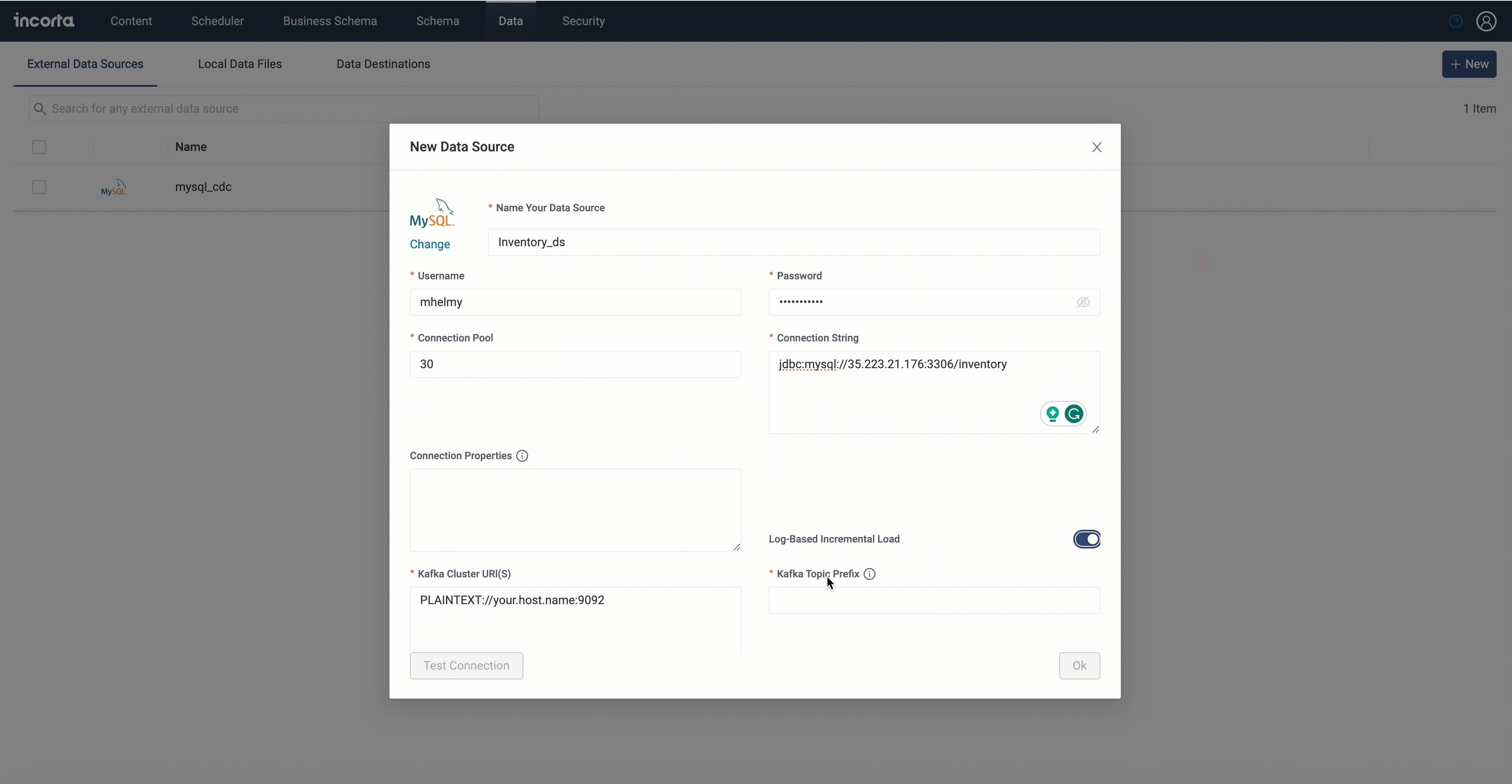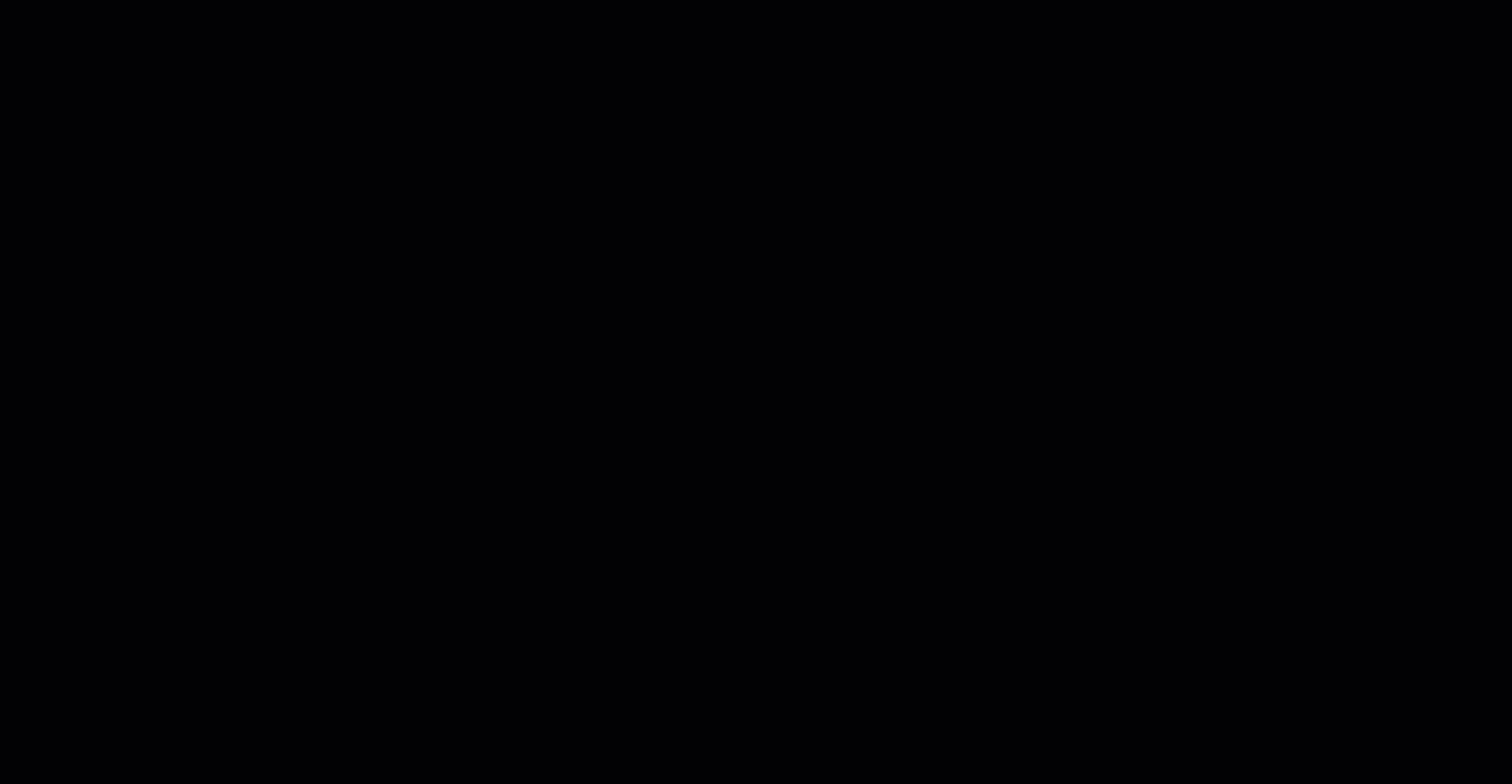
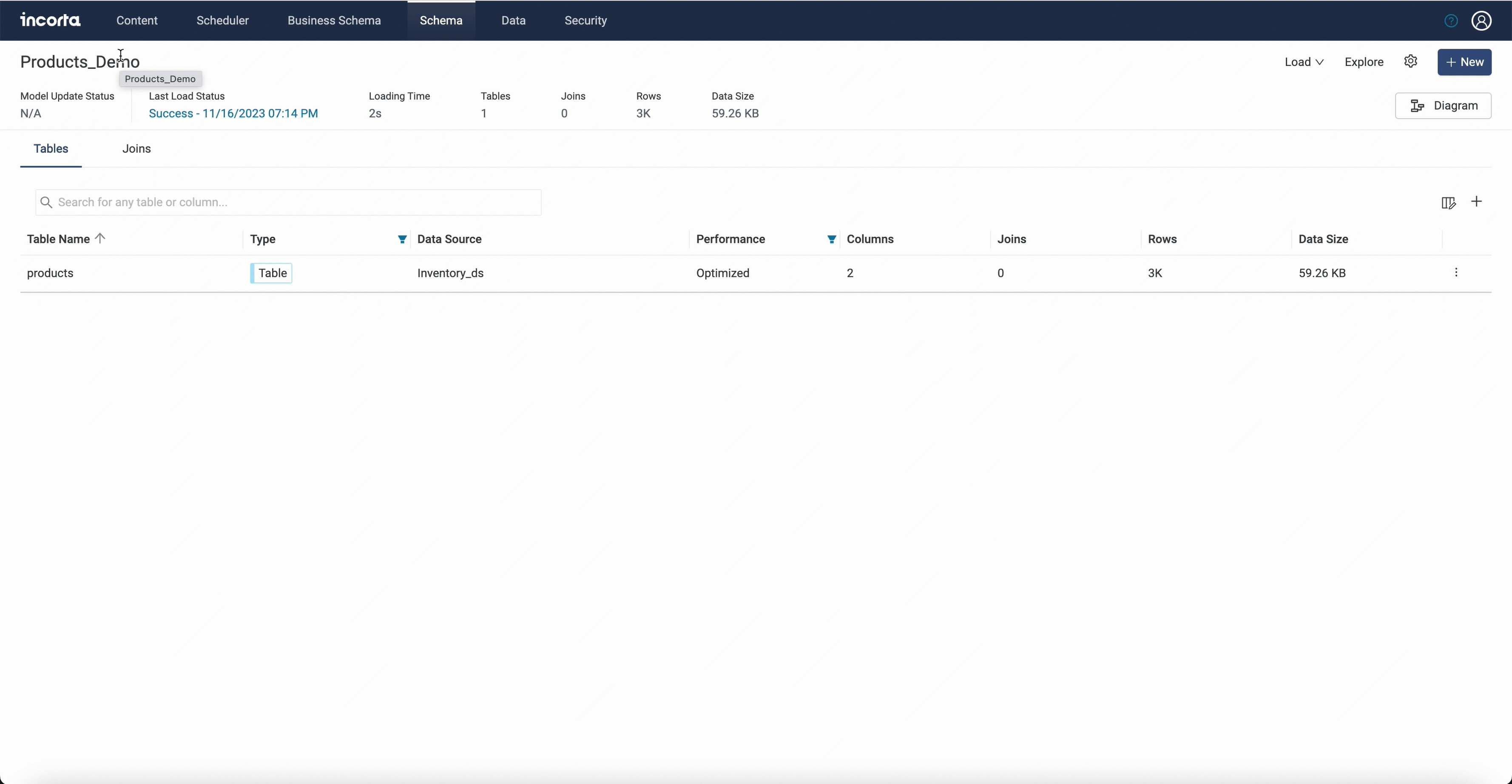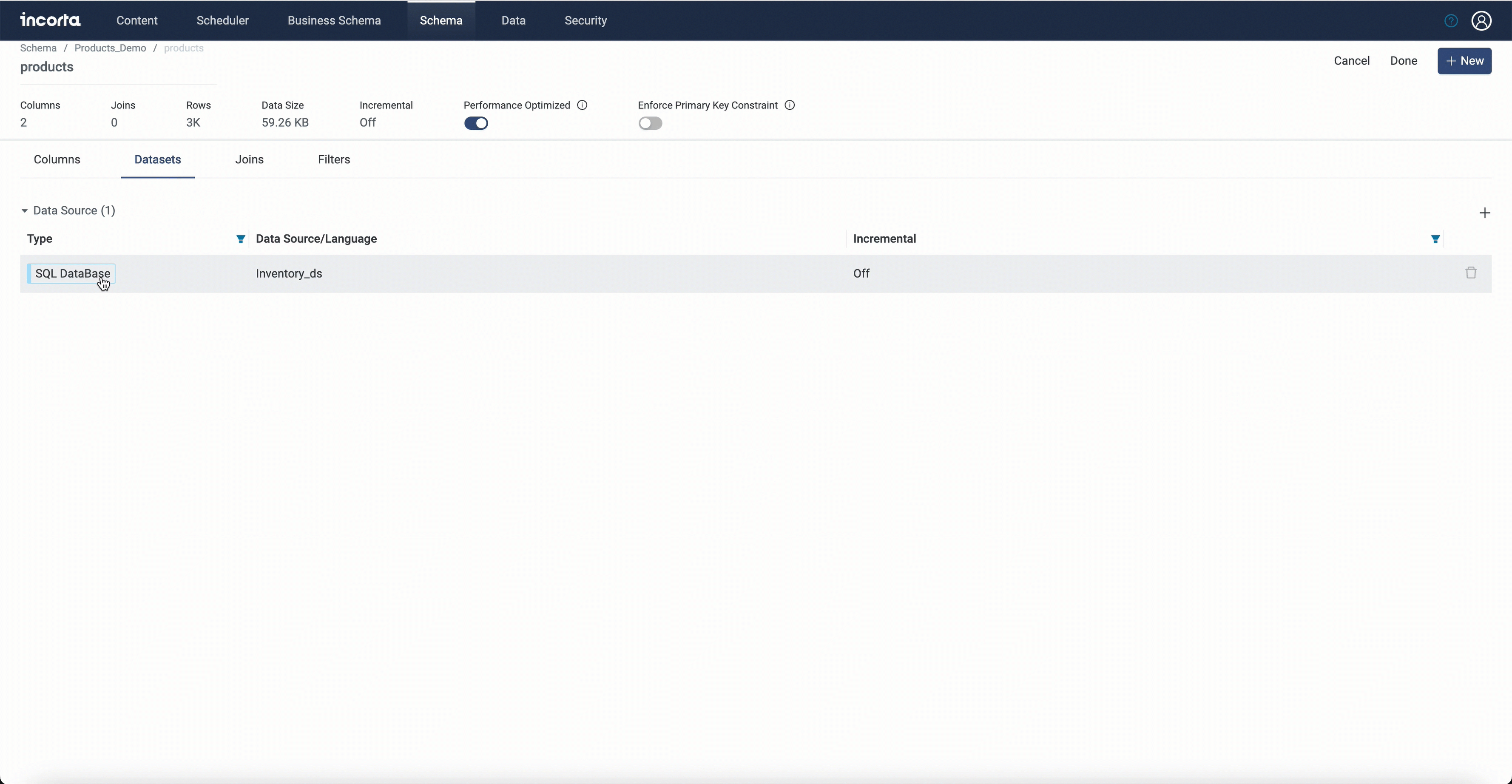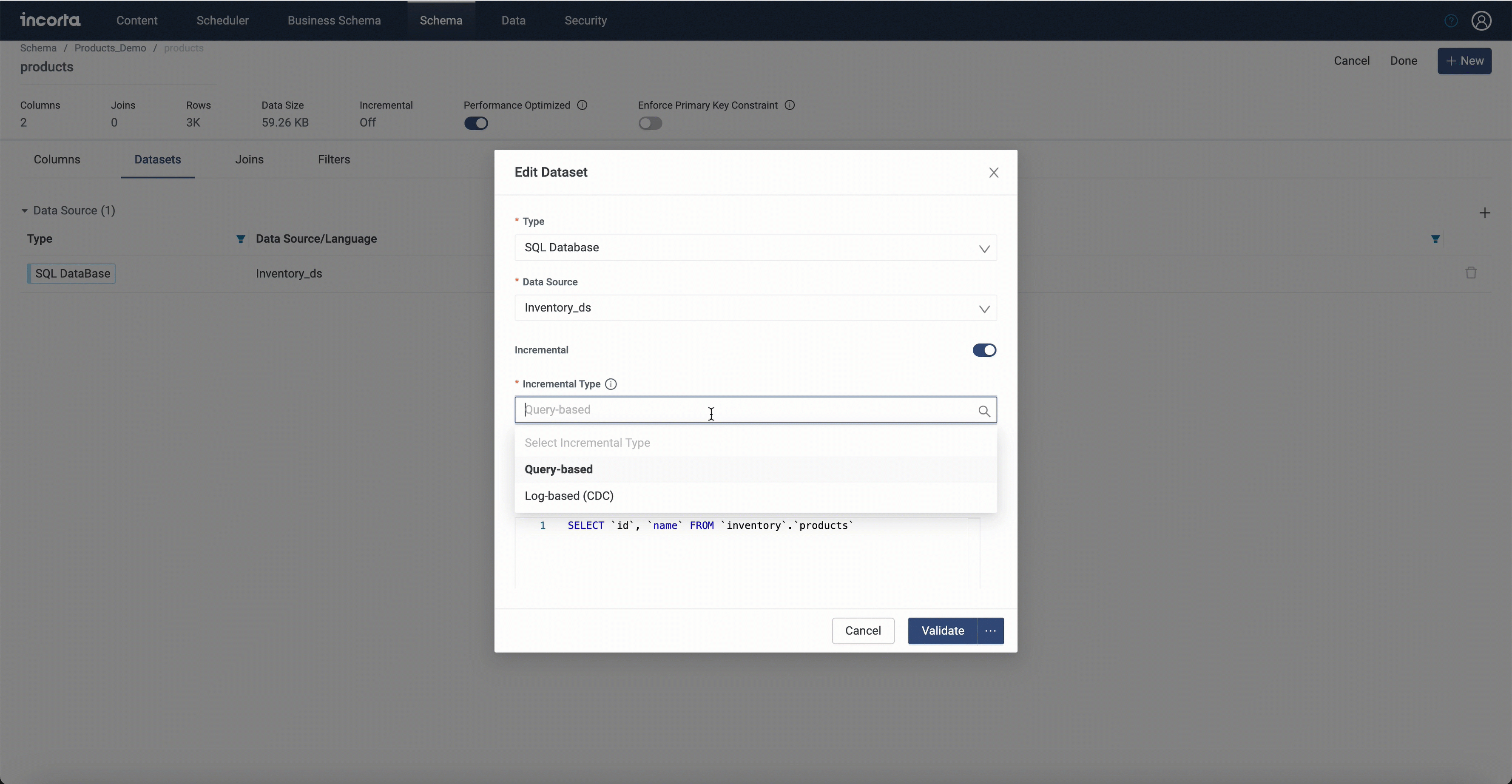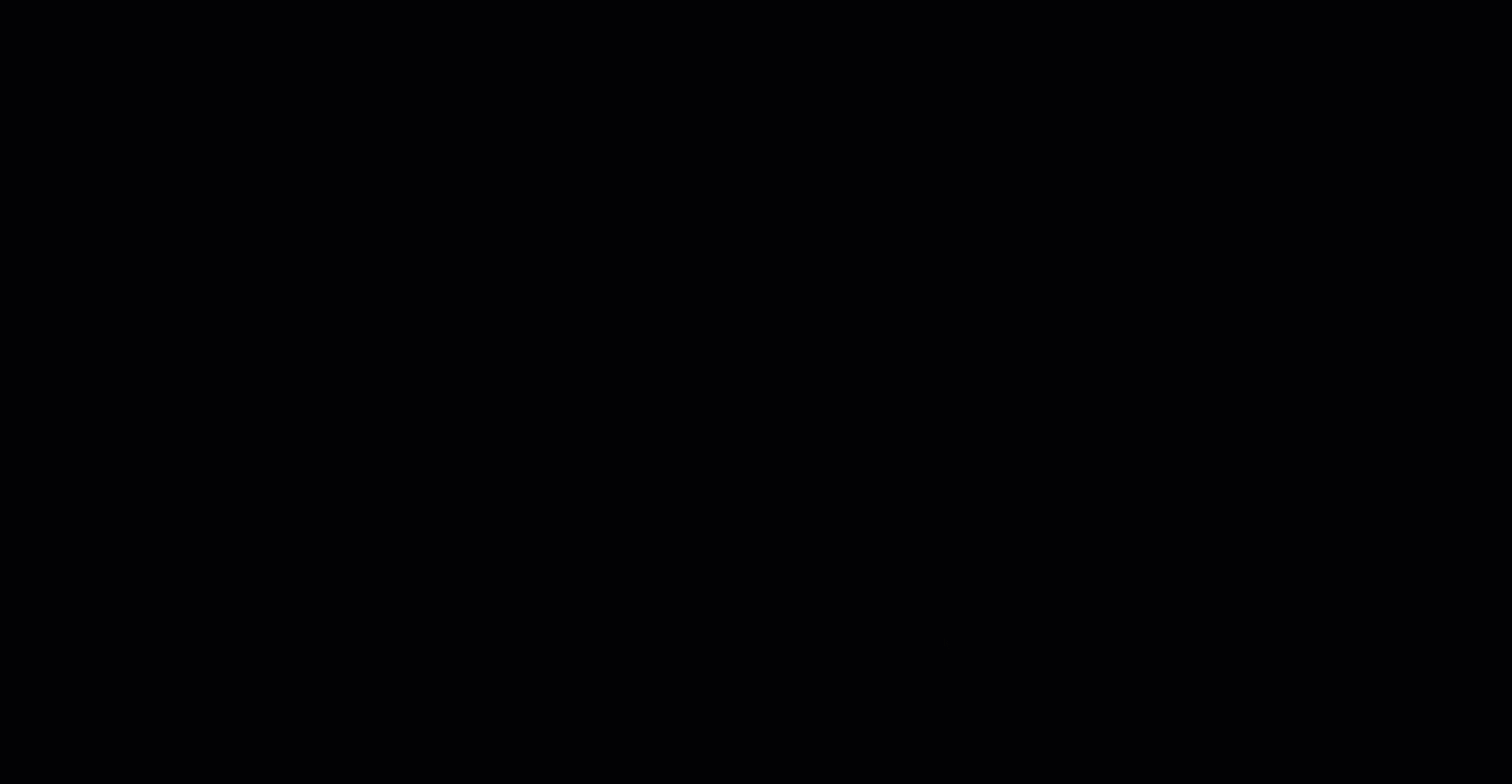
While creating a dataset for a physical schema, you can choose the log-based incremental load method to load this schema incrementally.
Data source connector configuration example using Debezium
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" localhost:8083/connectors/ -d ‘{"name": "inventory-connector1","config": {"connector.class": "io.debezium.connector.mysql.MySqlConnector","database.hostname": "127.0.0.1","database.port": "3306","database.user": "debezium","database.password": "debezium_1234","database.server.id": "184054","topic.prefix": "kafka_mysql","database.include.list": "inventory","schema.history.internal.kafka.bootstrap.servers": "127.0.0.1:9092","schema.history.internal.kafka.topic": "schemahistory.kafka_mysql","include.schema.changes": "true","column.propagate.source.type": ".*","snapshot.mode": "schema_only"}}’
Known limitations
- For the time being, Incorta does not track deletion updates through the log-based incremental load (CDC).
- In case of deleting records and performing full load, make sure to reconfigure the Debezium connector to avoid retrieving deleted records from the snapshot; knowing that this limitation is resolved starting connector version 2.0.2.2.
- Minimal mismatch in column INTERVAL data types.
- This feature supports Kafka topics that use a single partition only.
Incorta Data Delivery enhancements
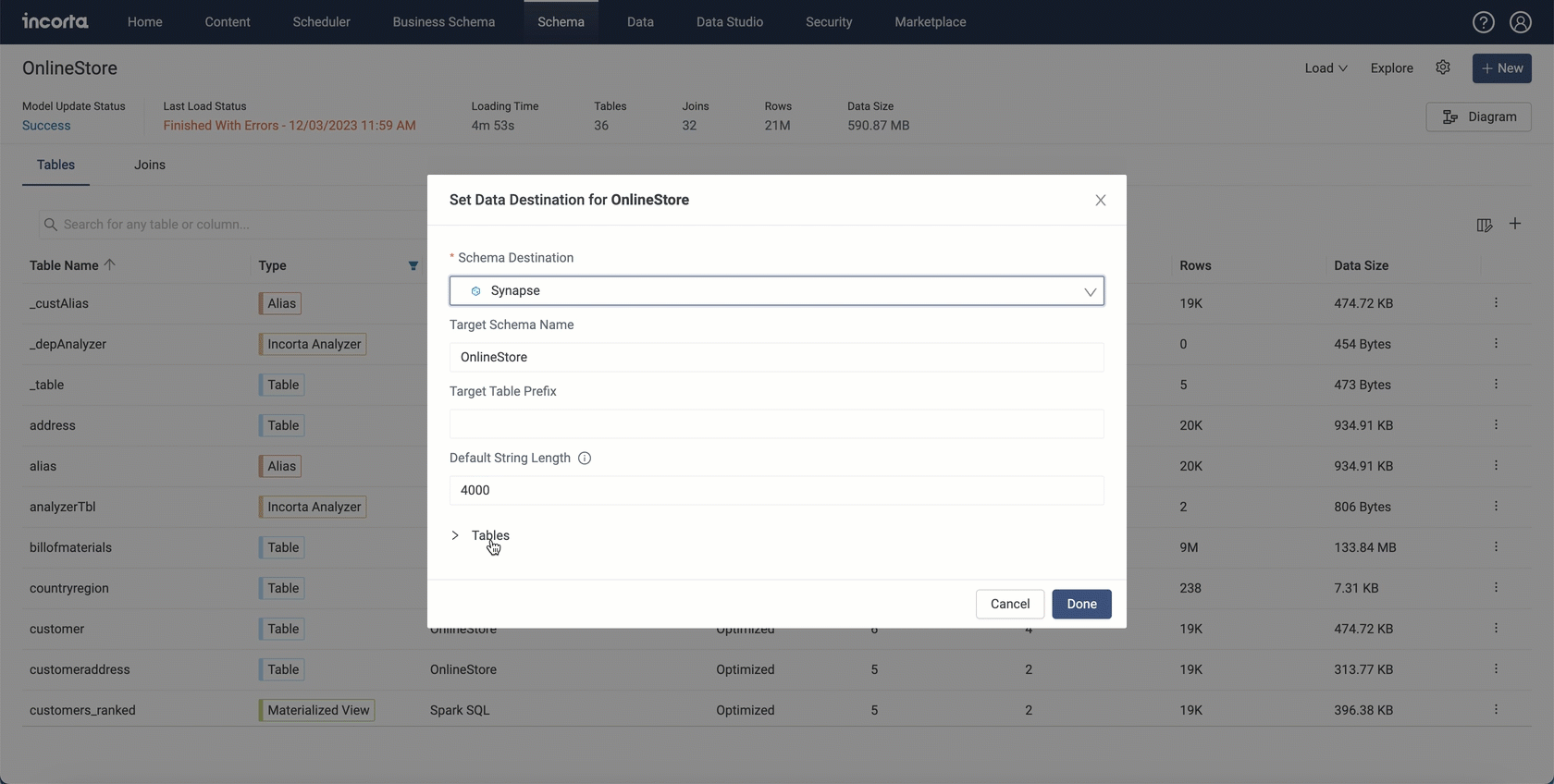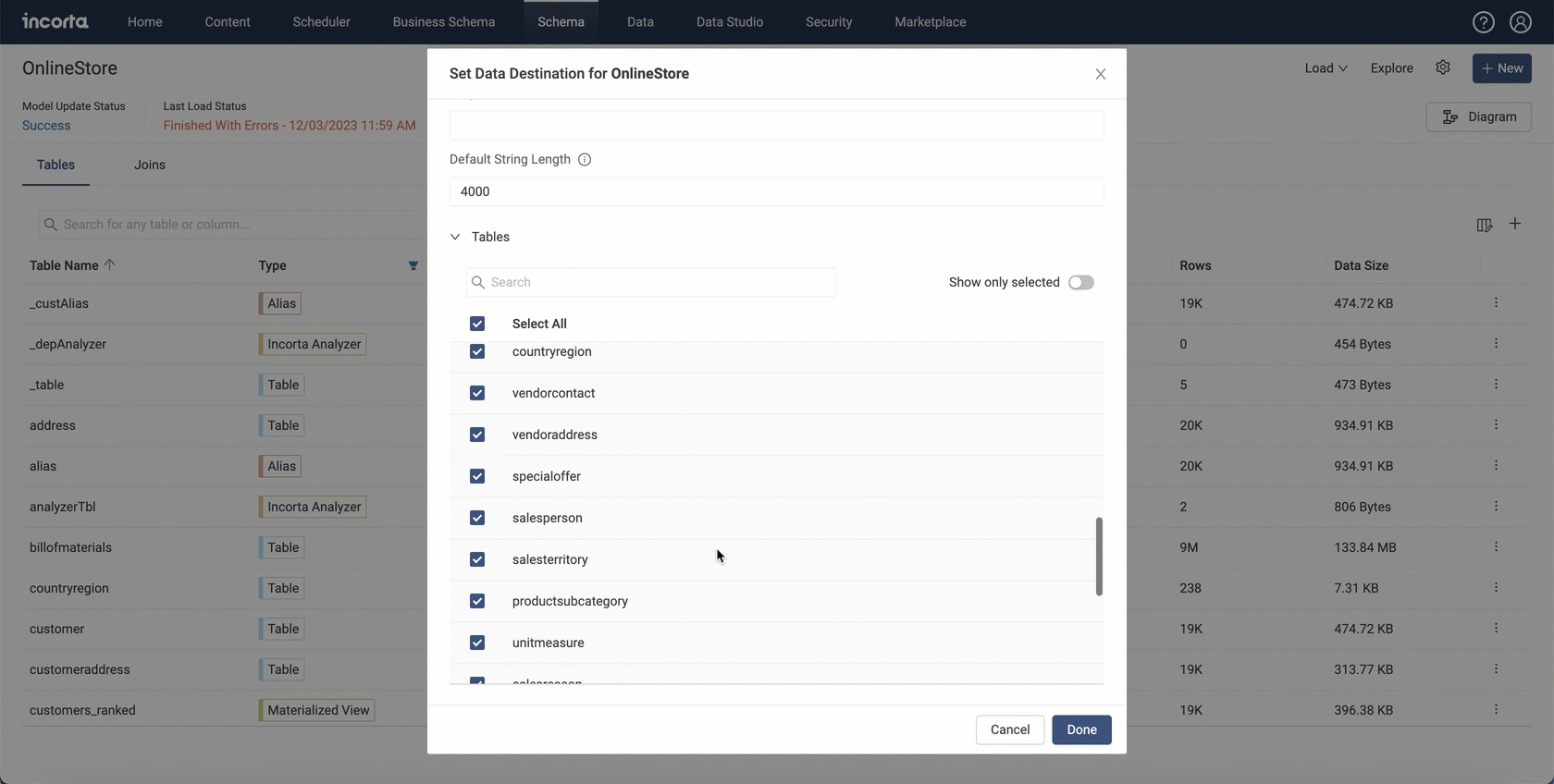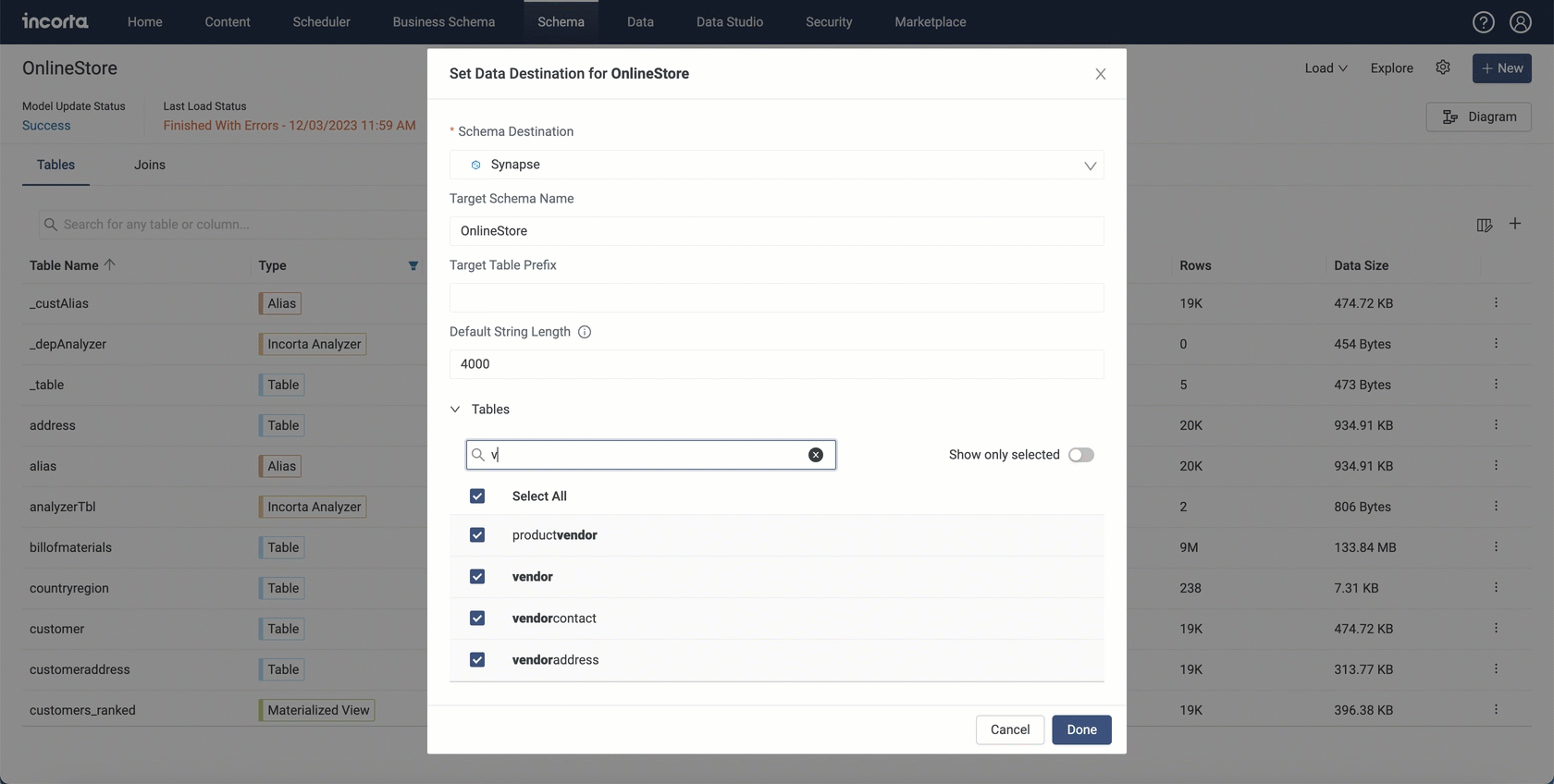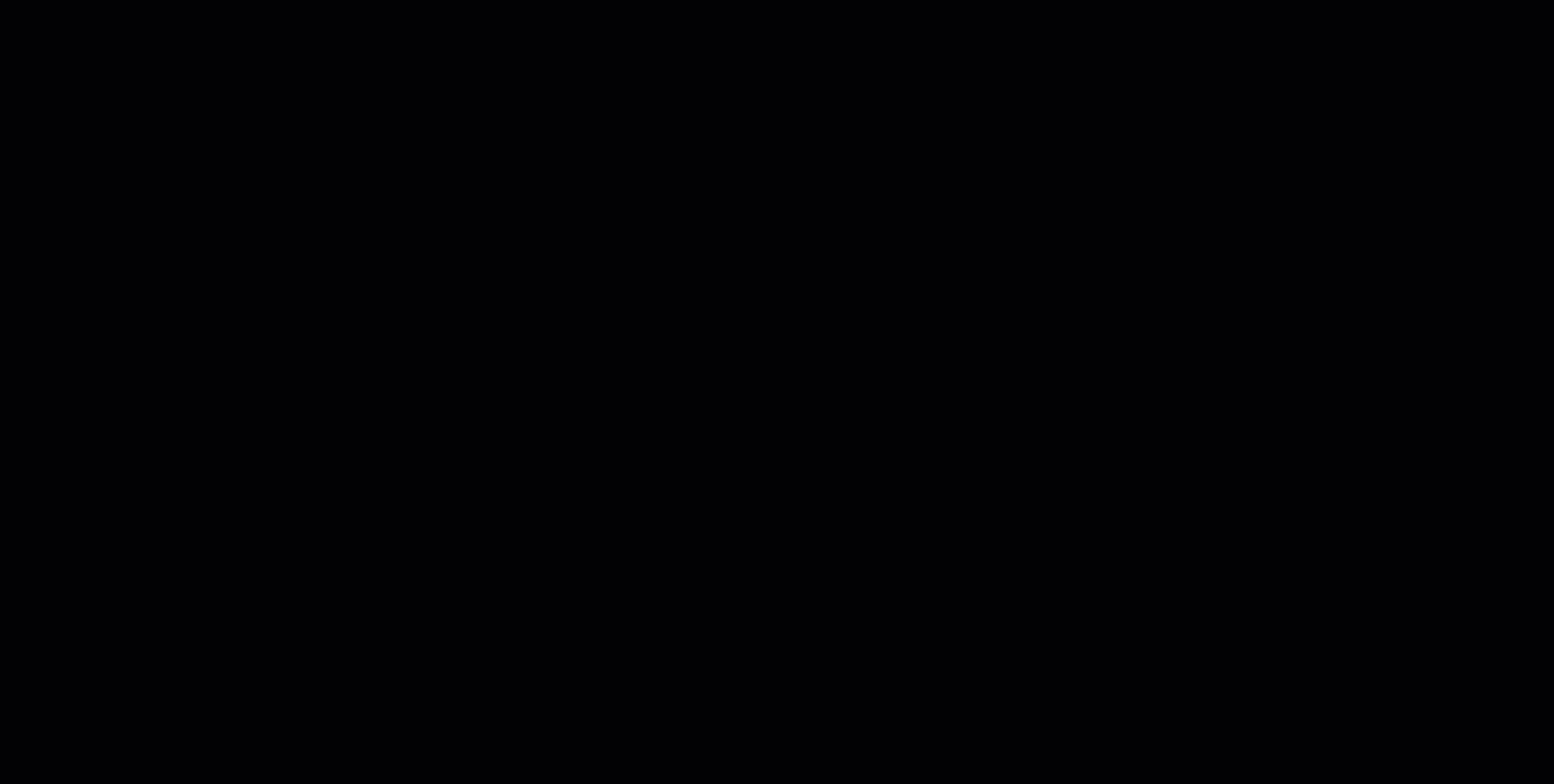
Now you can choose which tables to send to your data destination. While setting up a data destination for a schema, you find a new section that is collapsed by default called Tables. Using this section, you can configure which tables you want to send to the data destination during the load process.
Through the Tables section, you can filter tables by entering a keyword in the search bar. You will also find the Show only selected toggle that shows only selected tables when enabled.
Azure Synapse data delivery enhancement
For Microsoft Azure Synapse, Incorta now discovers and stores a column string length in the metadata. Hence, when you load your data and send it to the destination, the data is sent based on the discovered column length if it is available, otherwise, Incorta uses the Default String Length you have previously configured.
After upgrading to this release, Incorta can create the string length column with the next full ingest you perform if it is available.
There are cases where column length cannot be discovered, such as calculated columns or columns of data sources based on text files such as Excel and CSV files.
Date and number format at the view column level
Now, you can set the date and number formats per column or formula column in a business schema view. Once configured, this format will be the column’s default format whenever the column or formula column is added to an insight. However, you can still apply a different format to the insight column. You can also update columns in existing insights to inherit the view column format.
Notes:
- After upgrading to 2024.1.0, updating the view column format will not impact existing insight columns unless you configure insight columns to inherit the view column format.
- Changing the view column format affects all insights where the insight column inherits the view column format.
- Format updates at the view column level will not override the format specified at the insight column level.
- If no format is specified at the insight or view levels, the format will be as follows:
- Date columns: Short Date
- Timestamp columns: no format
- Numeric columns: no format, except for decimal columns
- You cannot set the default format for columns in Incorta Analyzer or SQL views.

SQL-compliant verified Business Schema Views
The Analytics Engine can now validate business views for compatibility with external BI tools and SQL compliance. This enhancement will empower you to make more informed decisions when selecting business views for your analytics and reporting needs. You can easily identify a verified business view by the green icon displayed next to it in the Business Schema Designer.
A Verified view is a business schema view that:
- Does not contain formulas referencing columns from Analyzer Views or SQL Views.
- Does not contain aggregation functions.
- Has a valid query plan, which means any of the following:
- A base table is explicitly defined and is valid for all the view columns (constitutes a valid join path).
- If there is no defined explicit base table, there must be a valid implicit base table connecting all columns in the view.
If the view does not meet any of the above criteria, it will not be considered verified. You can view the reason why it is not verified by hovering over the gray icon and clicking Show Details.

External BI tools connecting via the Advanced SQL Interface and Notebook for Analyzer users will have access only to the verified views in a business schema. However, external BI tools connecting via the classic SQL Interface will have access to both verified and non-verified views.
Current limitations and known issues
- This feature applies only to business schema views.
- Analyzer and SQL views are excluded from the verification process.
- If a view is considered unverified due to multiple reasons, only the first encountered one will be displayed.
- If a business schema view contains only session or global variables, it is considered unverified.
New Public API endpoints
This release introduces the following new endpoints:
Content Manager (Catalog) endpoints
- Search Catalog (
catalog/search): searches for dashboards and folders that a user owns or has access to in the Content Manager (Catalog) and its subfolders by a defined keyword. - List Catalog Content (
catalog): lists folders and dashboards that a user owns or has access to in the root directory of the Content Manager (Catalog). - List Catalog Folder Content (
catalog/folder/{folderId}): lists folders and dashboards that a user owns or has access to in a specific folder in the Content Manager (Catalog).
Load plan execution and status endpoints
- Execute Load Plan (
/load-plan/execute): executes a specific load plan and returns the load plan execution ID. - Load Plan Execution Status (
load-plan/status/{execution-id}): returns the status of a load plan execution, with or without the details per load group, schema, or object.
New Date functions
This release introduces the following new Date functions:
- yearQuarter(date_timestamp exp): Returns an integer that represents the year and quarter of a given date or timestamp column or expression. In the returned value, the first four digits represent the year while the last two digits represent the quarter. Example: this function,
yearQuarter(date("2023-10-25")),returns 202304. - yearQuarter(): Returns an integer that represents the current year and quarter. In the returned value, the first four digits represent the year while the last two digits represent the quarter. Example: 202401.
- yearMonth(date_timestamp exp): Returns an integer that represents the year and month of a given date or timestamp column or expression. In the returned value, the first four digits represent the year while the last two digits represent the month. Example: this function,
yearMonth(date("2023-10-25")), returns 202310. - yearMonth(): Returns an integer that represents the current year and month. In the returned value, the first four digits represent the year while the last two digits represent the month. Example: 202401.
Incorta Copilot Configuration
Incorta Copilot is the new AI feature that integrates with several Incorta modules and enables users to analyze data, build insights, and write code blocks simply by asking questions in natural language.
Incorta supports the integration with OpenAI, the copilot is currently integrated within the Analyzer, Dashboards, Data Studio, Business Schema, and Notebook.
Currently, the copilot is a preview feature, to use it please contact the Incorta Support.
After Incorta avails the copilot for you, the CMC admin must log in to the CMC and go to Clusters > cluster-name > Cluster Configurations > Server Configurations > Incorta Copilot to turn on the Enable Incorta Copilot toggle and provide the Azure OpenAI or OpenAI information needed to complete the integration.

You must restart the Analytics service when you enable and configure the copilot. Knowing that any future change in any of the values will require restarting the Analytics service as well.
For more information refer to Guides → Configure Server.
Copilot for Dashboard
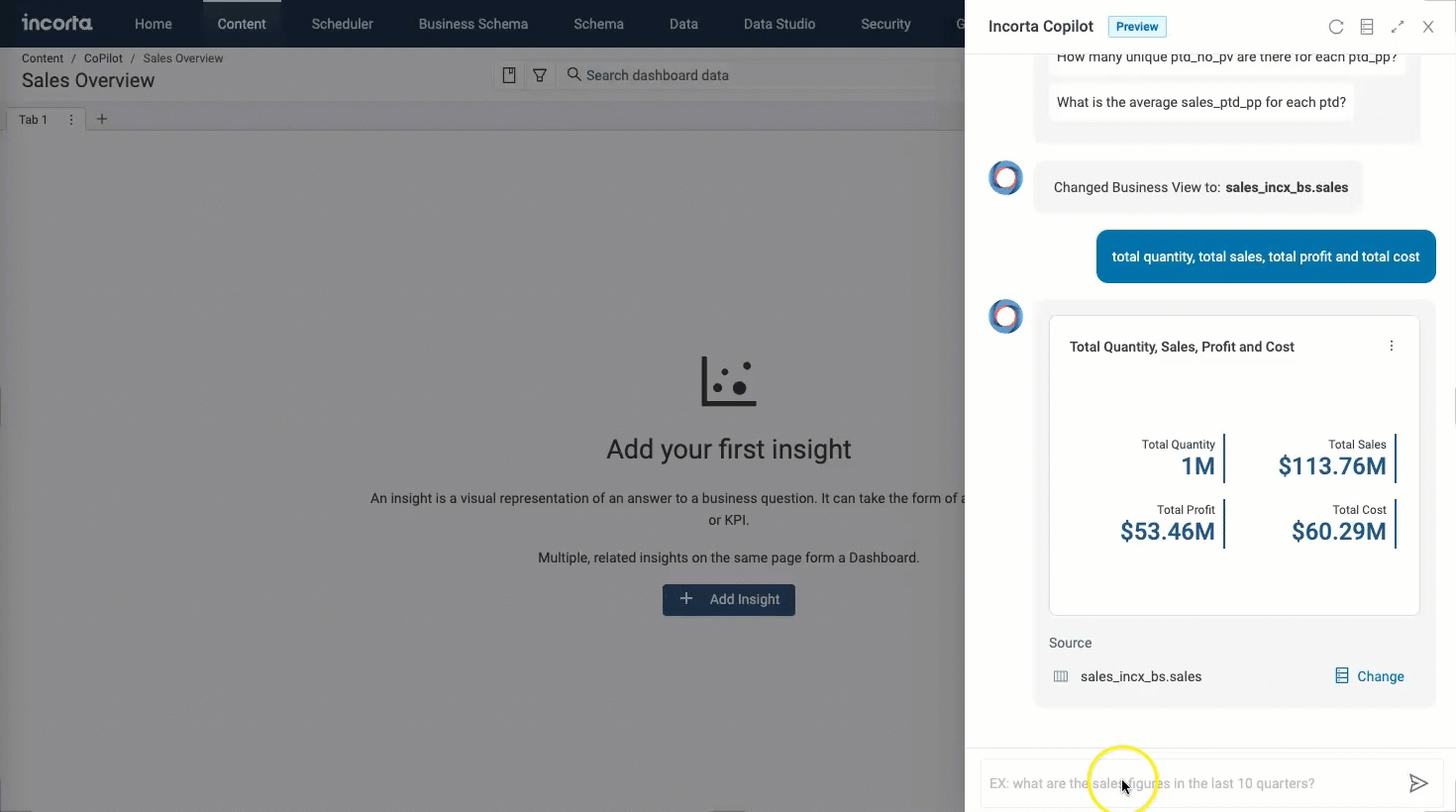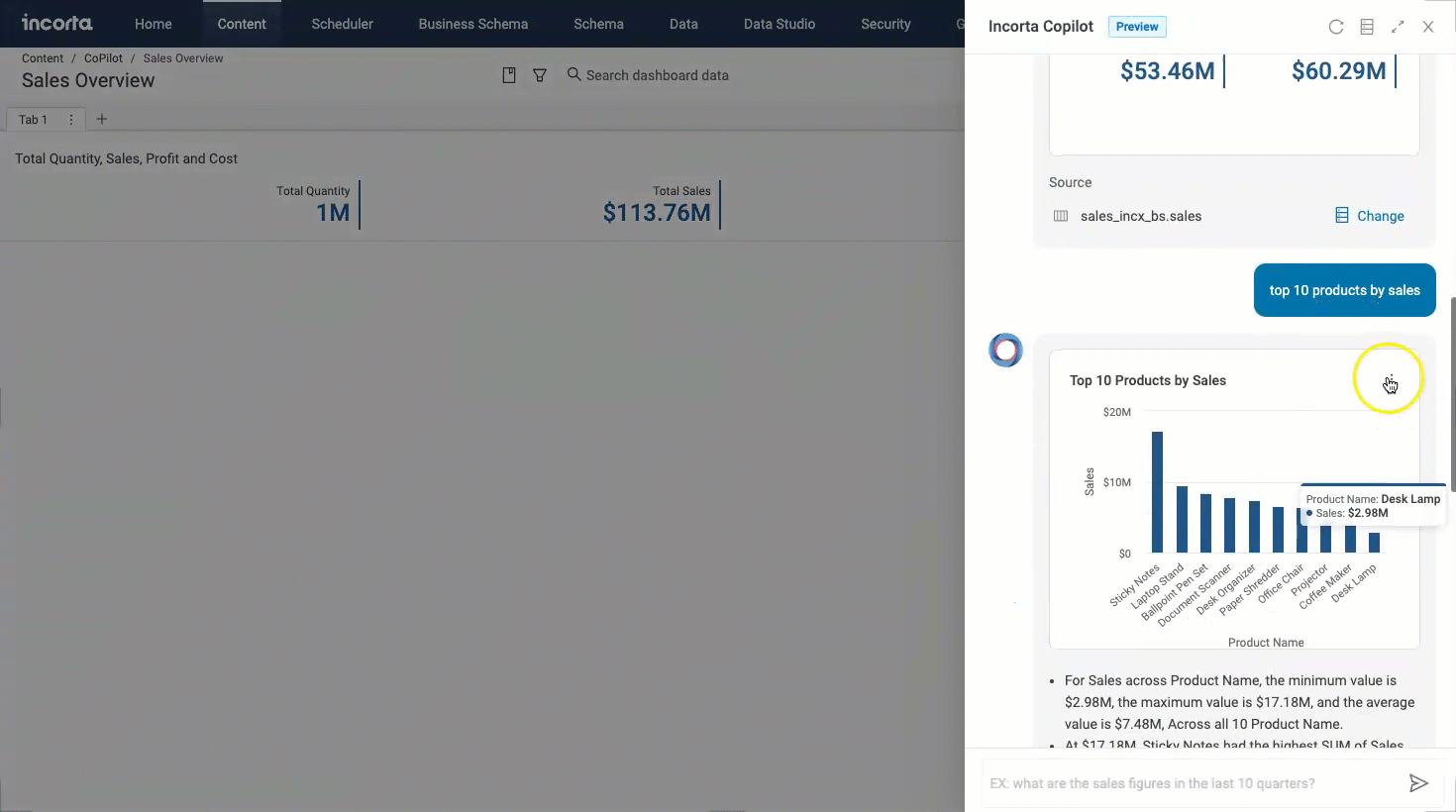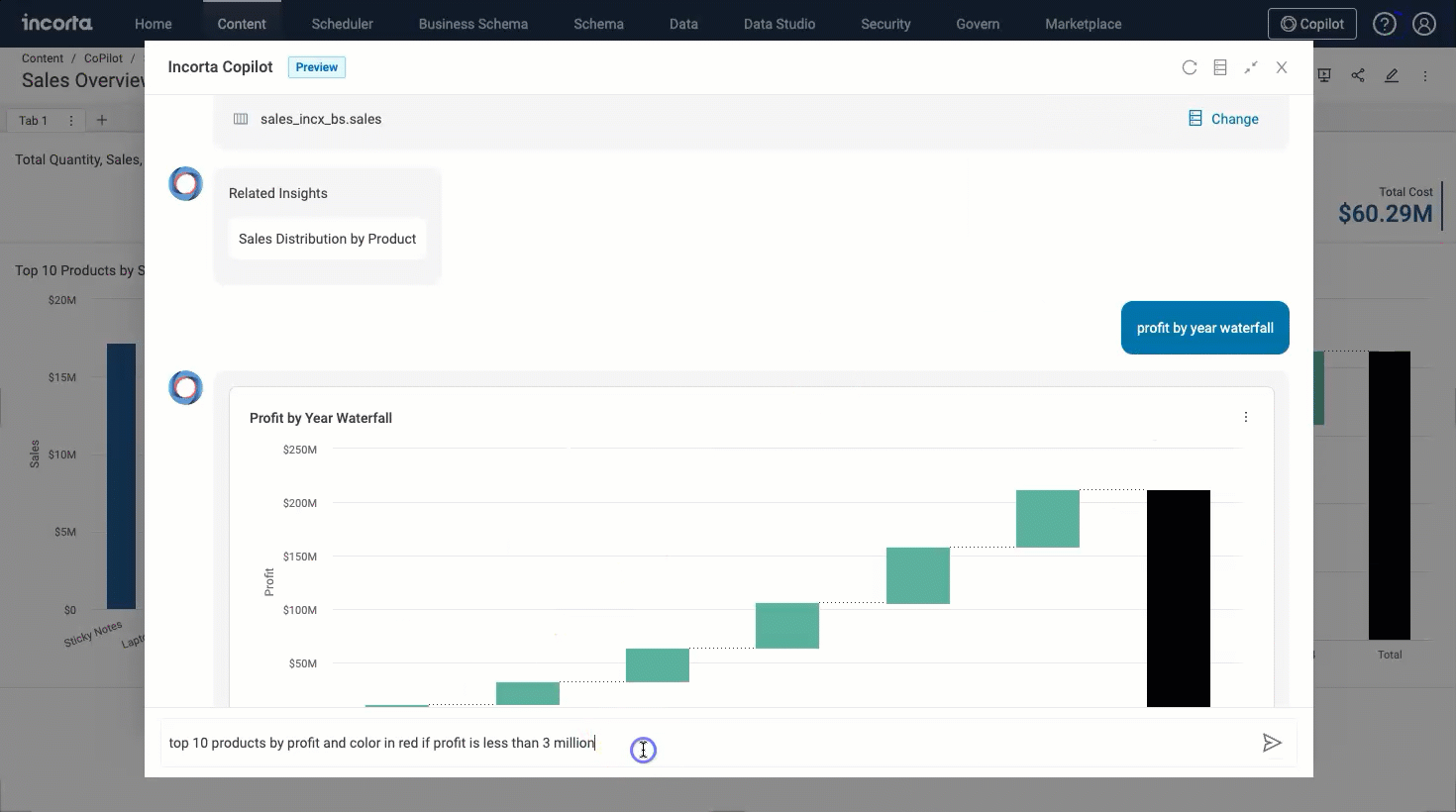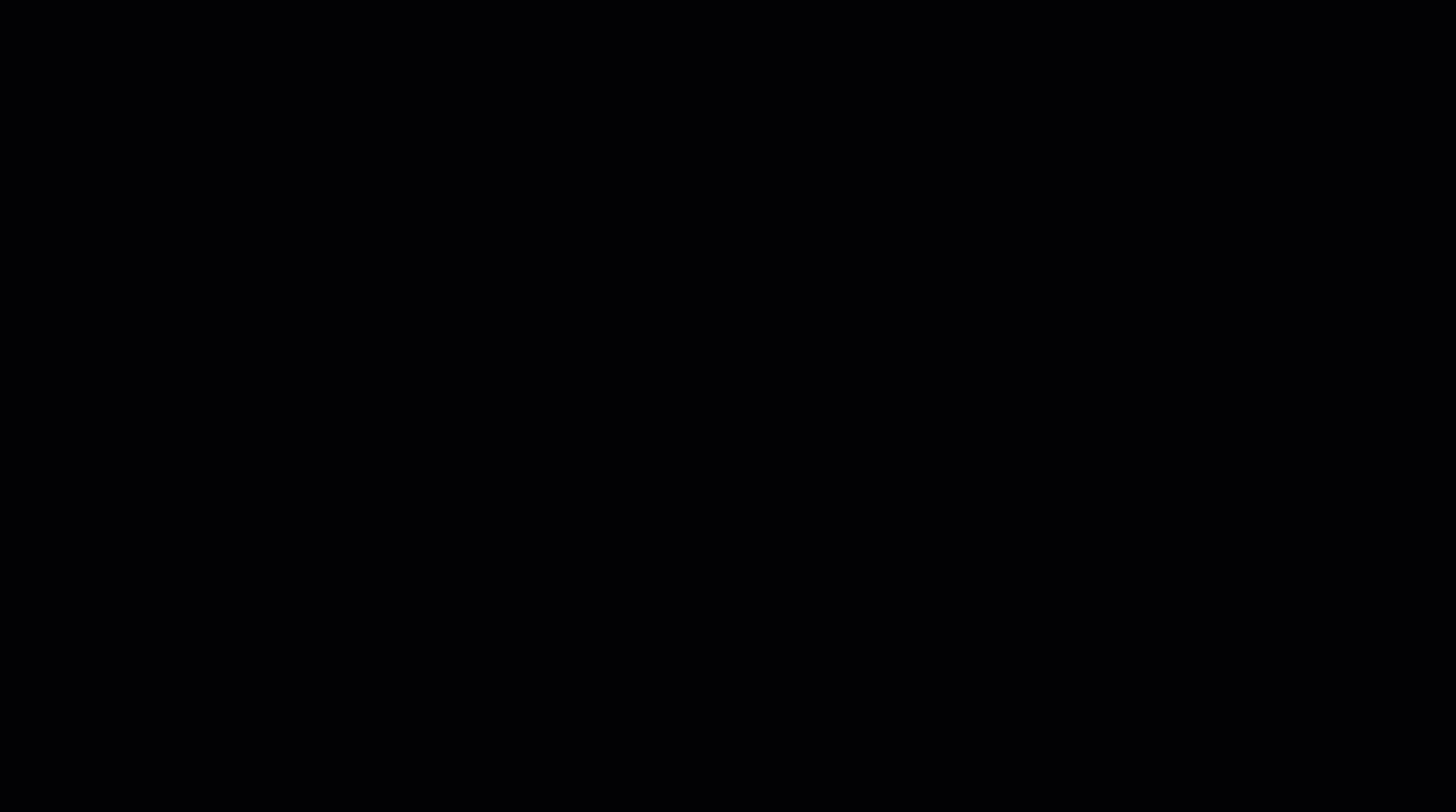
Copilot in dashboards enables users to directly query the data they have access to and find relevant insights in existing dashboards. Incorta Copilot in dashboards can suggest questions to help you understand the data and uncover new insights.
You will be able to use the copilot in dashboards using the Copilot button in the header menu. When you select it, it opens a chat window where you can type in your questions and hence get your answers.
Copilot for Notebooks
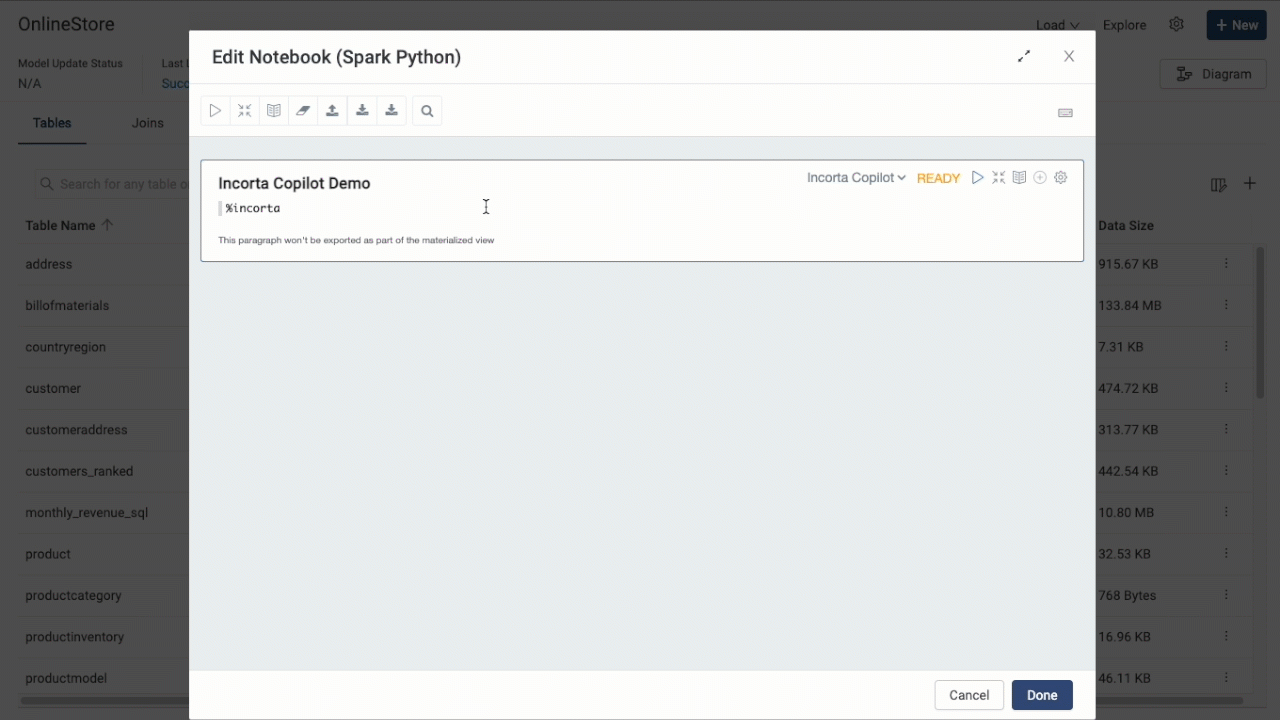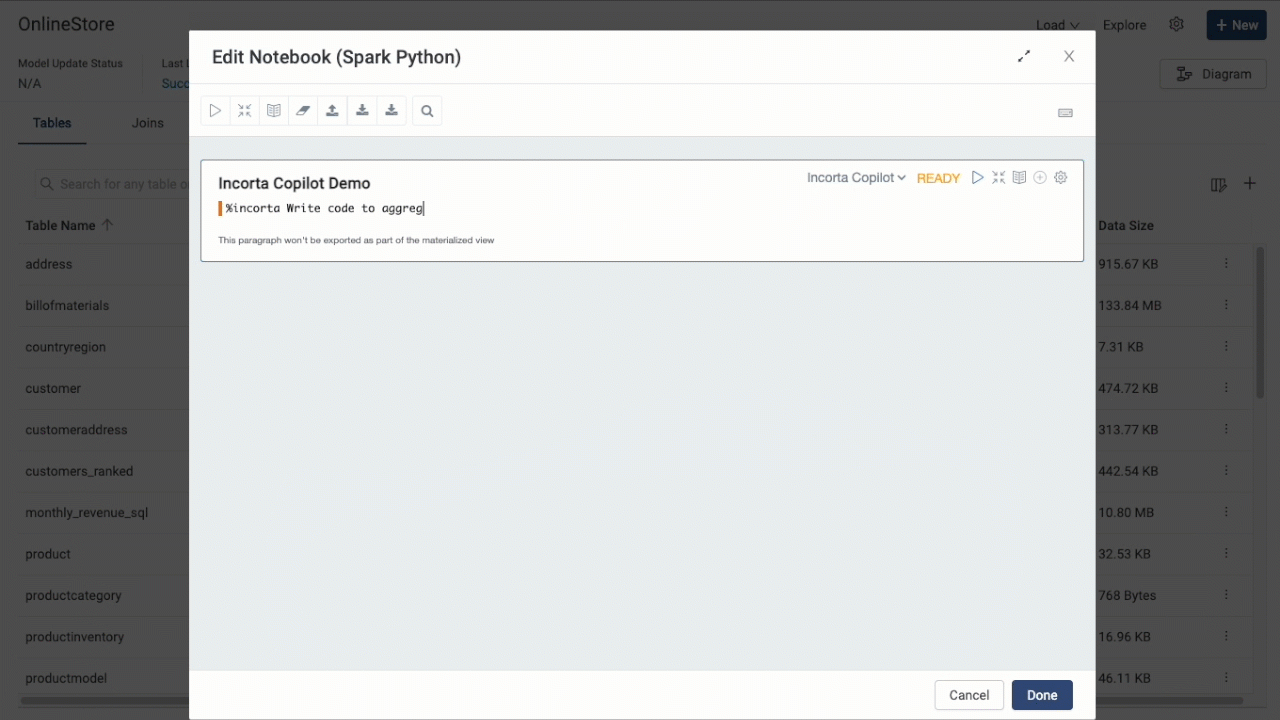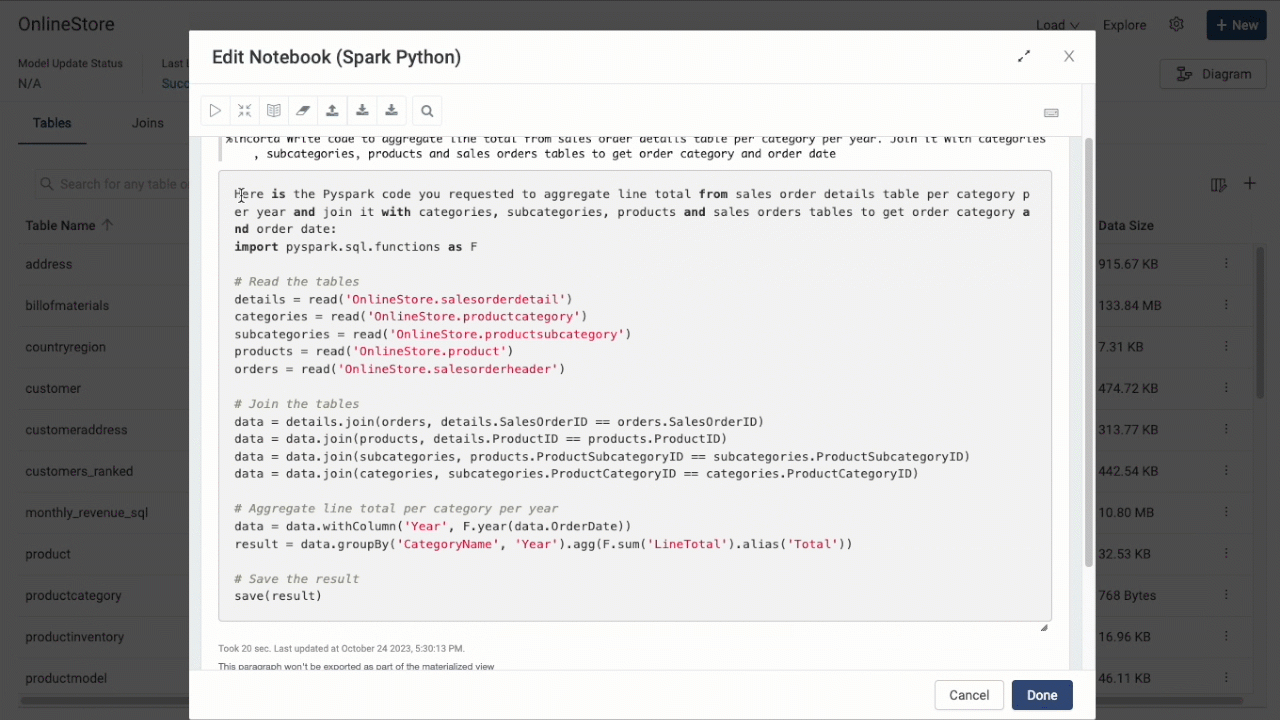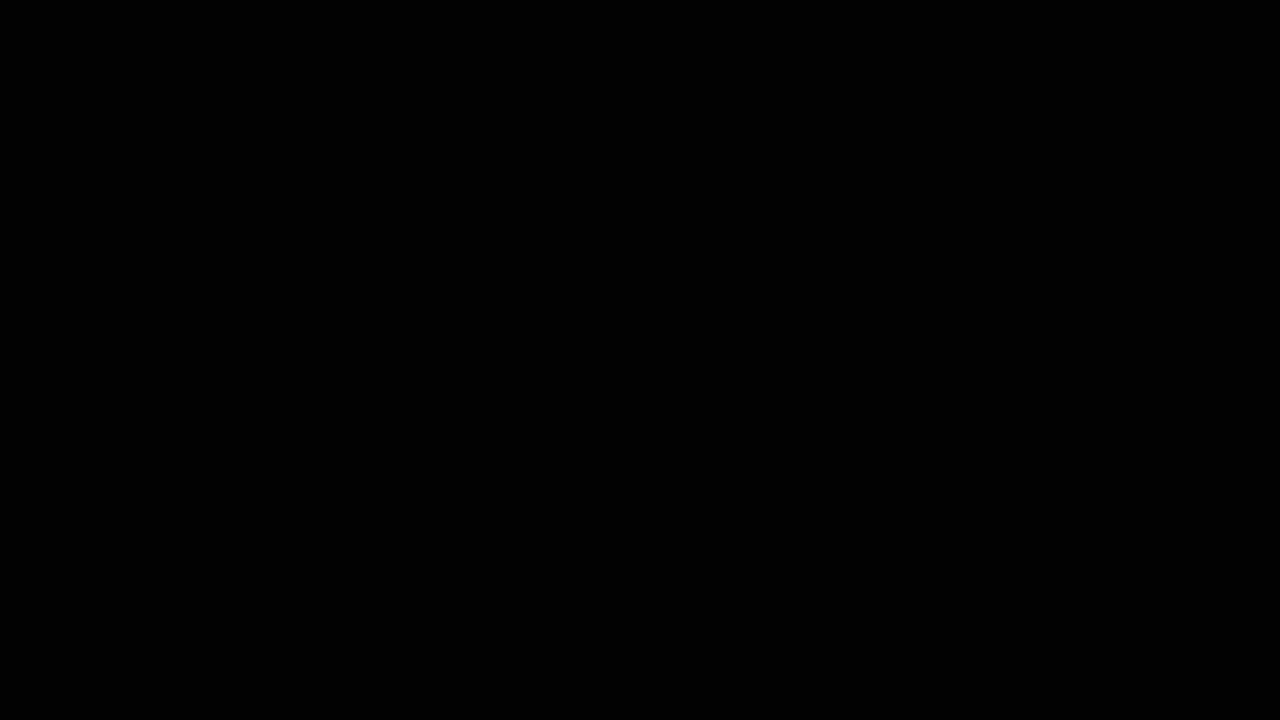
The copilot also exists in Notebooks, where it can help you debug your Notebook code, or even write it. Make sure to choose Incorta Copilot as your engine, and then start typing in your questions within the Notebook paragraph.
The feature is still maturing, and more enhancements are to follow in upcoming releases. If you need more information, please contact the Incorta Support.
Copilot for Notebooks provides usage of a secondary model, which you can enable from the CMC under Clusters > cluster-name > Cluster Configurations > Server Configurations > Incorta Copilot > Use Secondary Model.
Changing any of the configurations requires restarting the Analytics service.

Copilot for Notebooks Overview
Copilot for Data Studio
Copilot for Data Studio exists in multiple recipes that can help you achieve your goal by typing in the needed description in natural language to enter your code or query statement.
You can use the copilot in the following recipes:
- Custom Code
- Data quality
- New column
- SQL
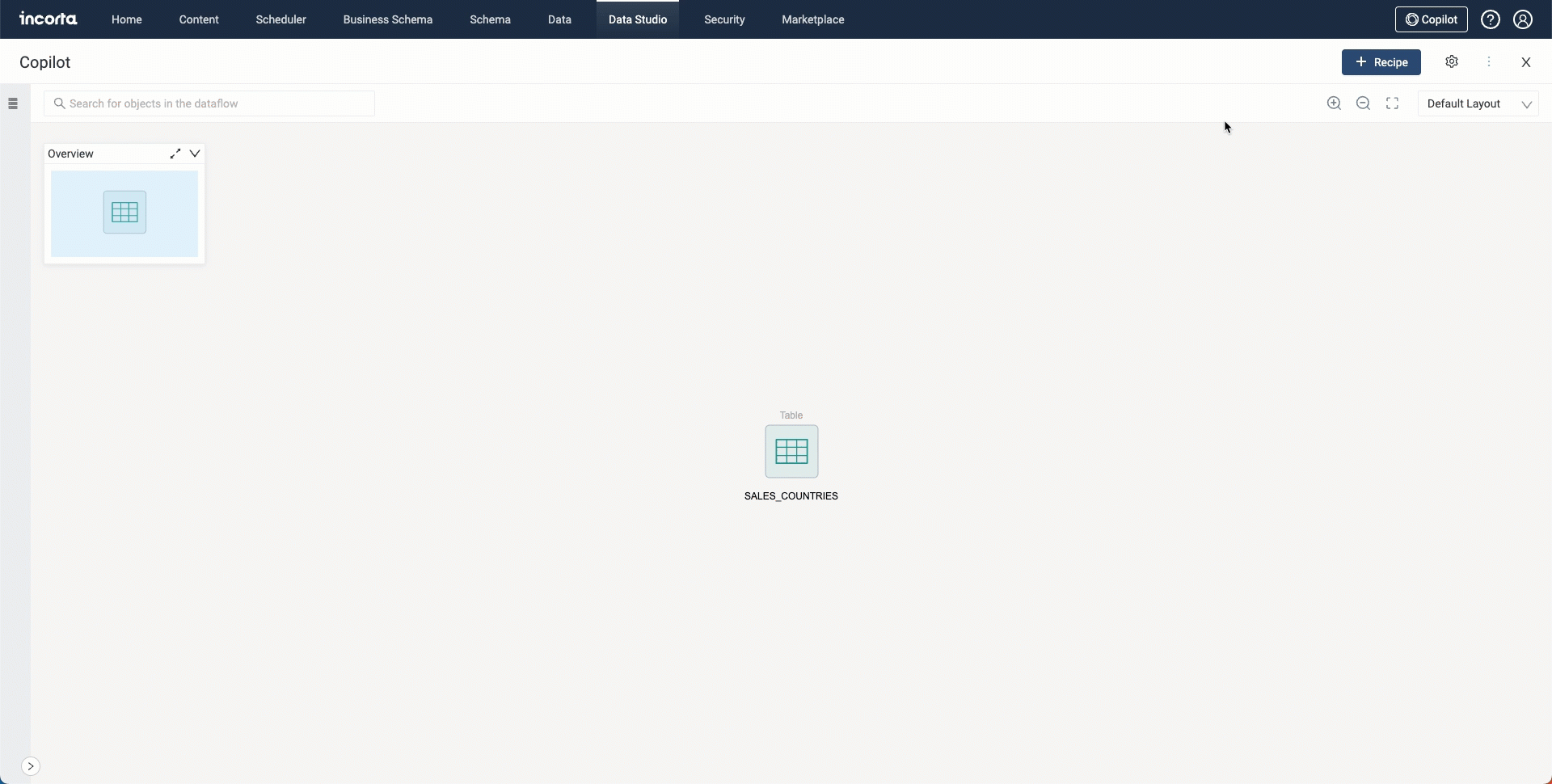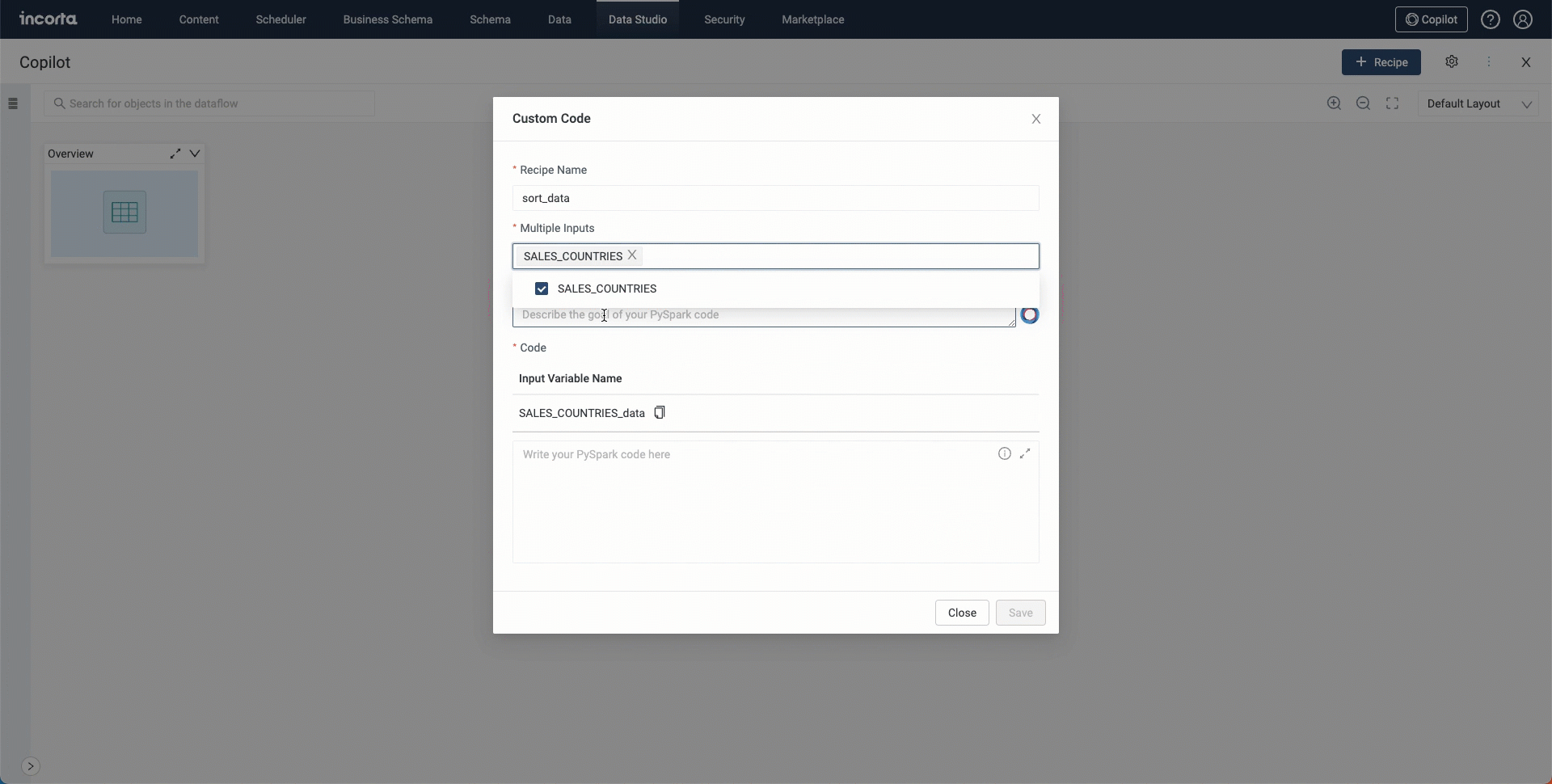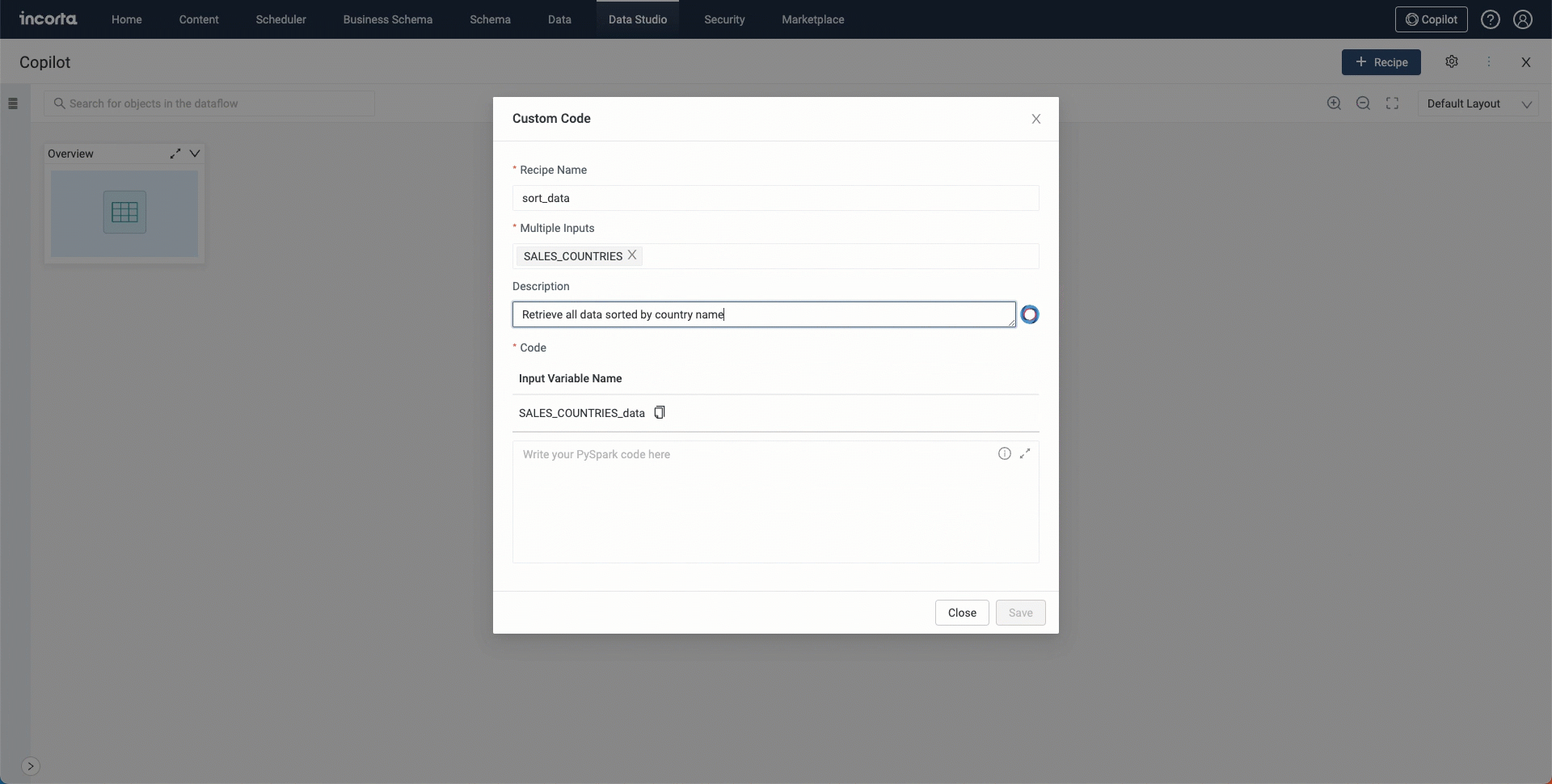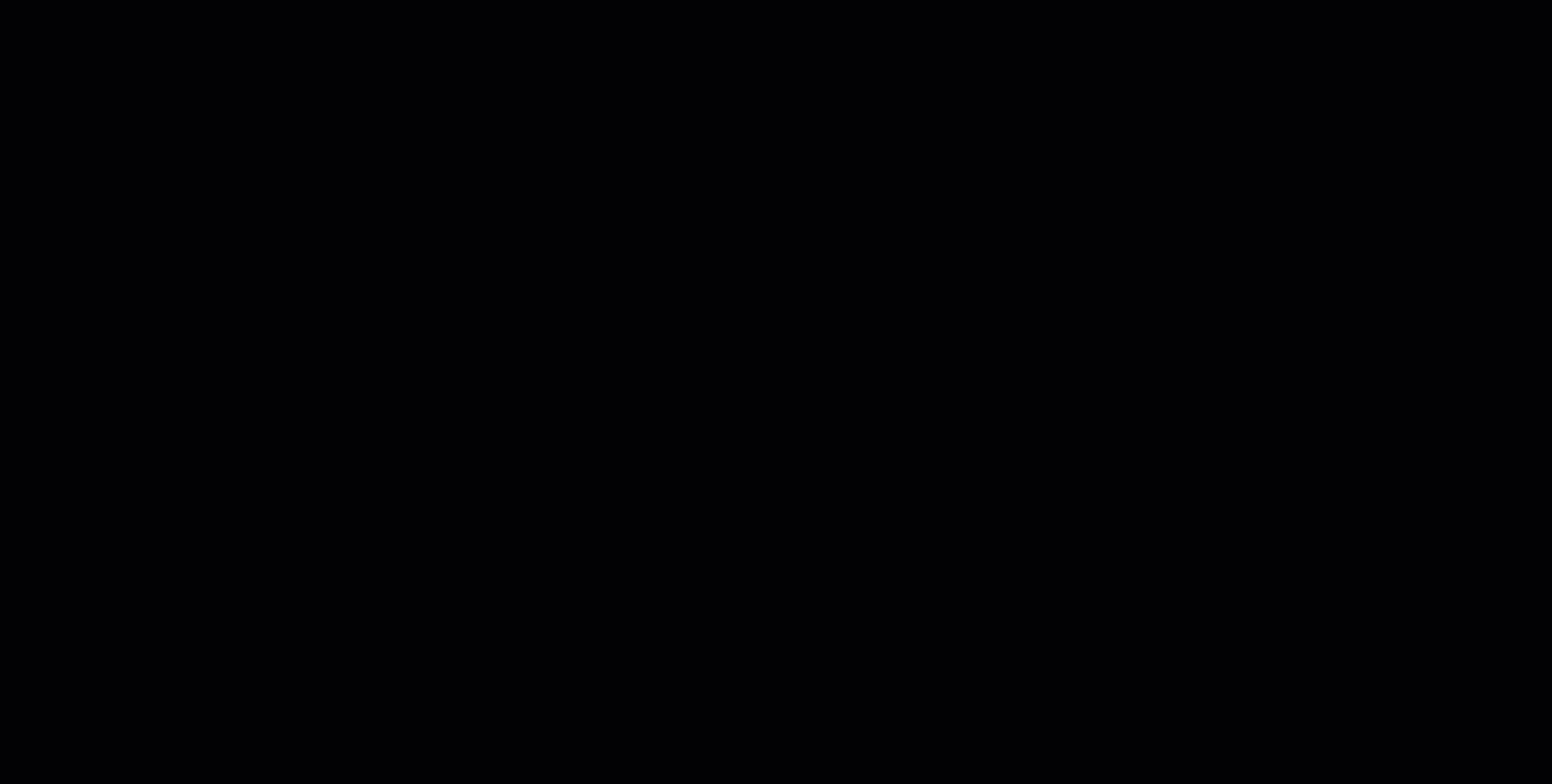
AI-supported features for business schemas
In this release, you can use the integrated AI tools to generate and suggest descriptions and labels for business schema columns, allowing for:
- Providing more accurate and consistent descriptions and labels.
- Reducing manual effort.
- Ensuring data clarity.
The AI tool creates and suggests column labels based on the column name while it generates and suggests column descriptions based on the table and schema names. You can select one or more columns to generate descriptions or labels for.
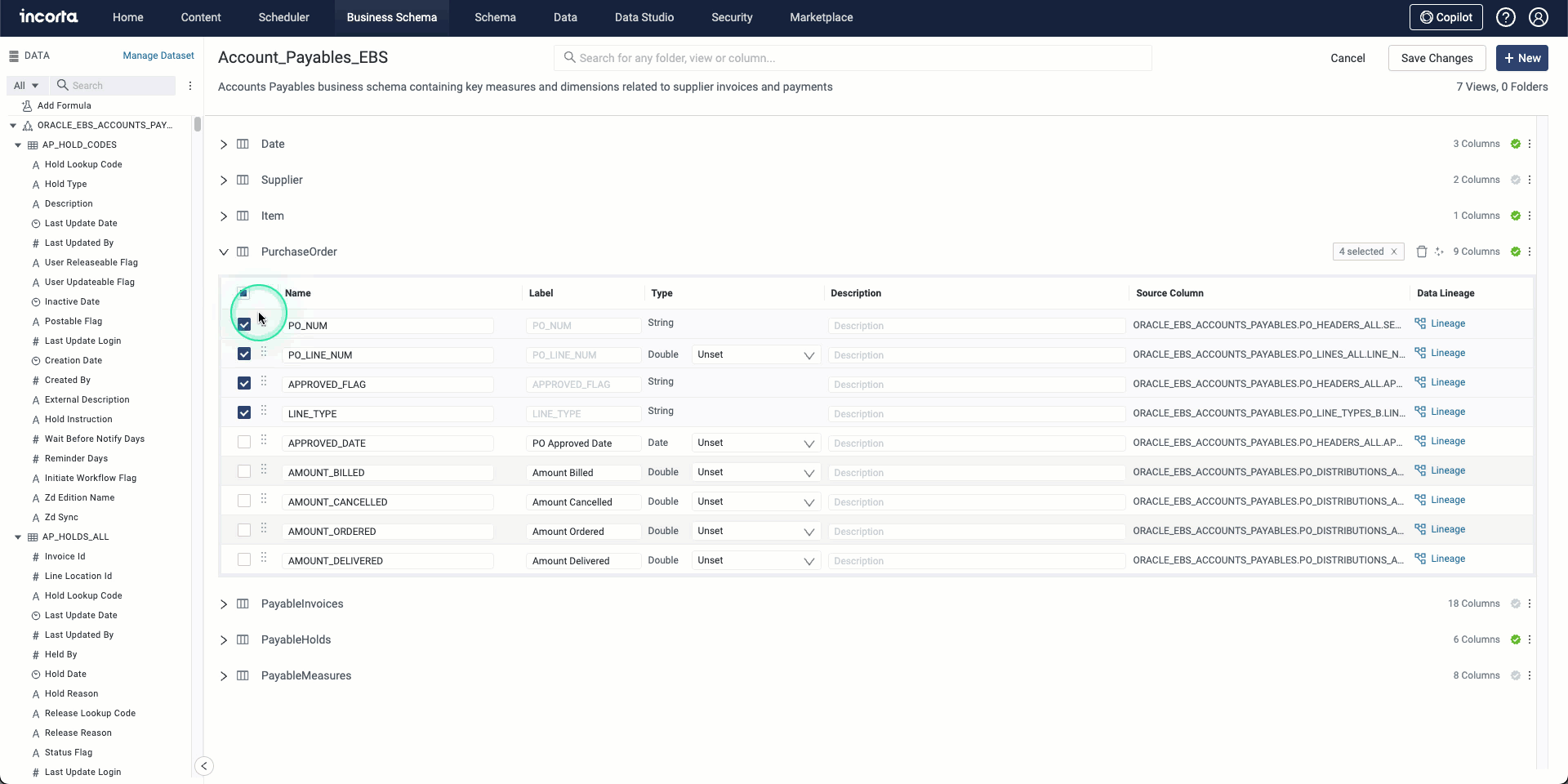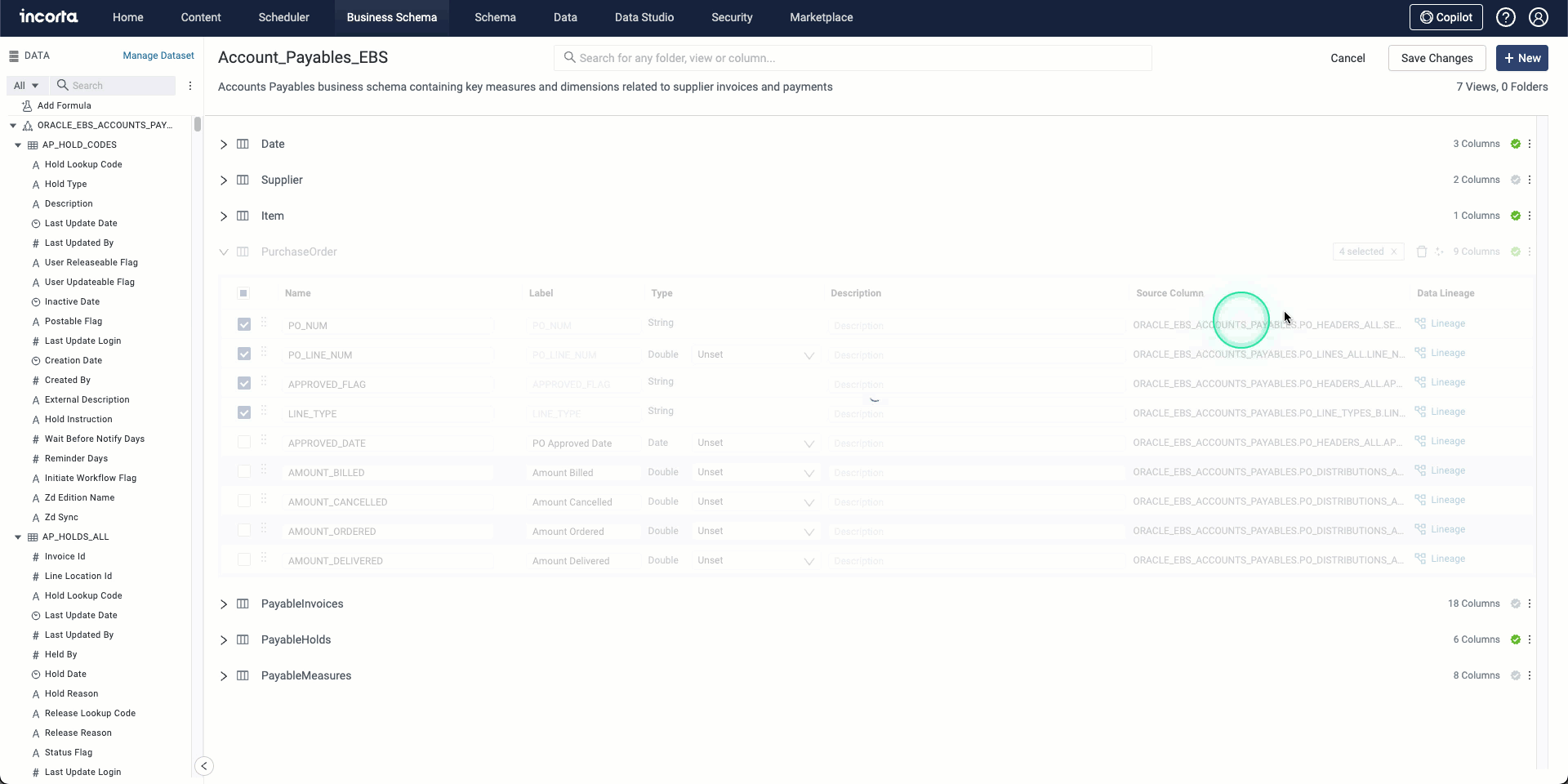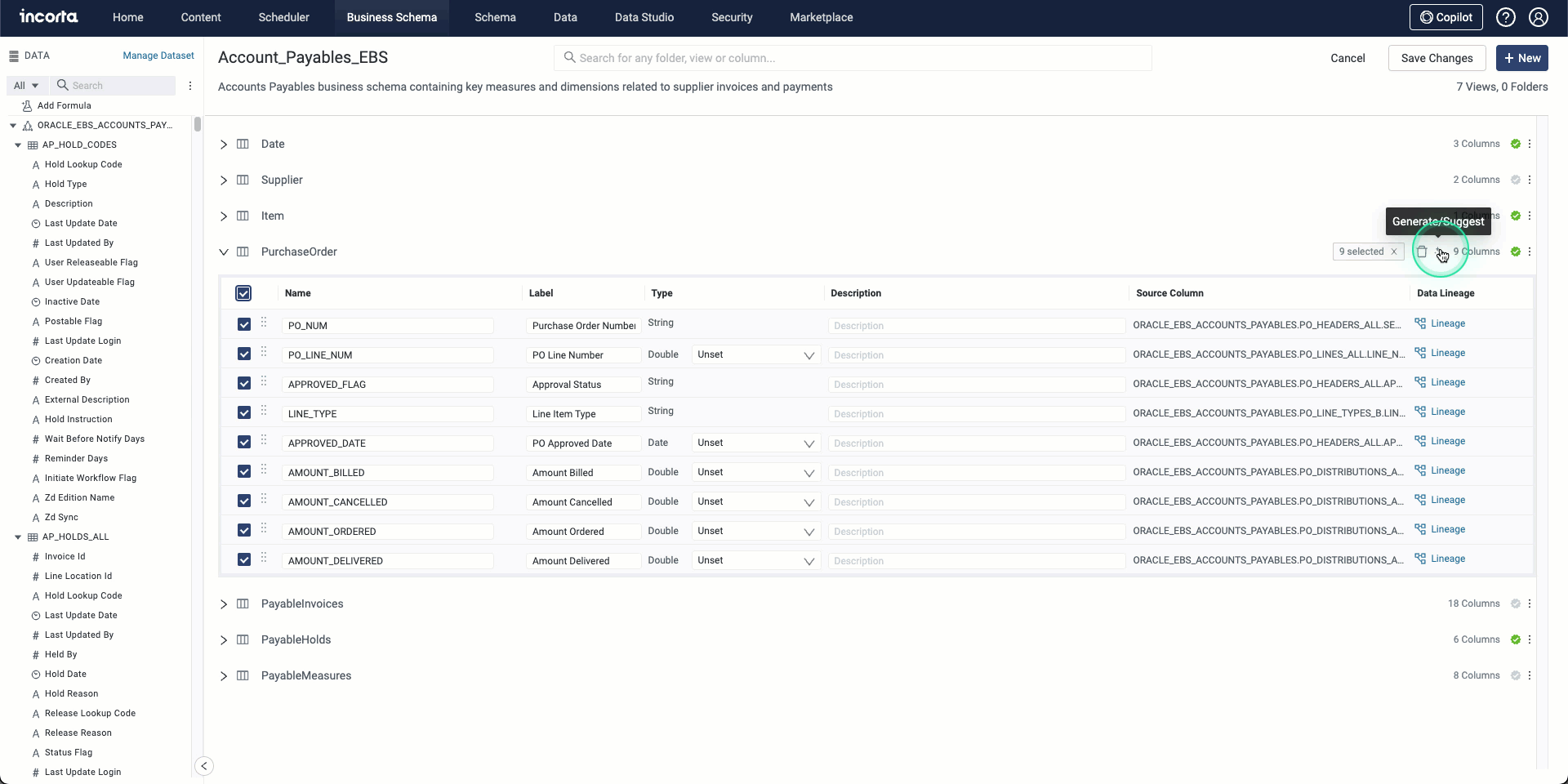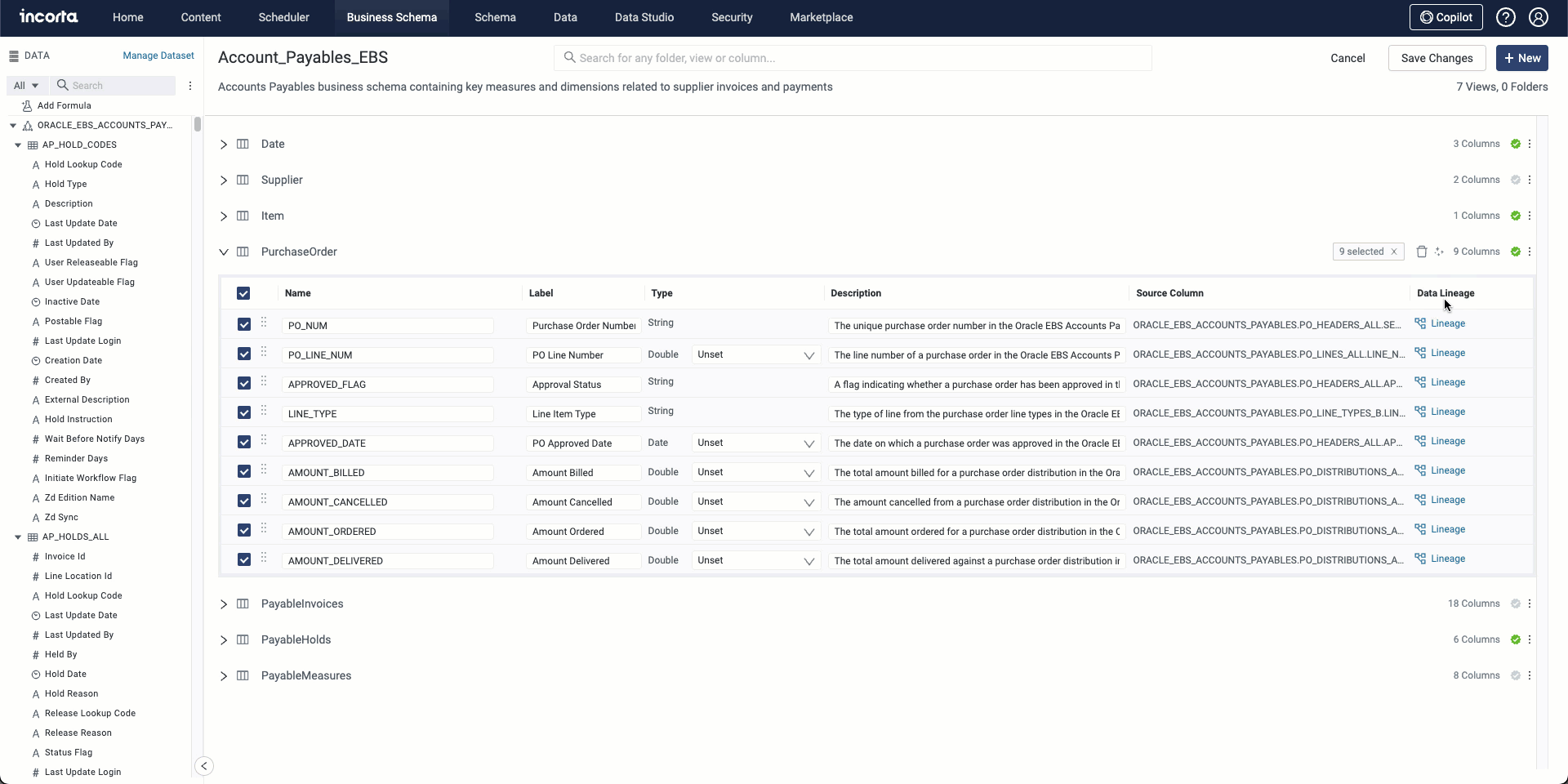
Semantic search for view columns
By integrating with Copilot, Incorta has expanded the search capabilities within the business schema list to include business view columns. This enhancement allows for semantic searches for columns across all business schemas on the list, even supporting searches in multiple languages. When searching in the business schema list, the results include both columns that semantically match the search term and business schemas that exactly match it.
Enhancements to data load notifications
This release introduces significant enhancements to data load notifications, including notifications on load plans instead of schemas and a new notification type for jobs that take more time than expected.
Load plan notifications
Now, you can create data load email notifications at the load plan level rather than the schema. The Schema Notifications tab is no longer available and is replaced by the Notifications tab.
- The notifications list will show only notifications that the logged-in user has created. However, the Super User and users with the SuperRole will have full access to all notifications.
- Deleting a load plan deletes its data load notifications.
Upgrade considerations
Existing schema load notifications will be migrated to load plan notifications during the release upgrade process. Each schema load notification will be automatically assigned to all single-schema load plans for this schema. The migration process will not migrate schema notifications to load plans having multiple schemas. Additionally, schemas with no single-schema load plans will not have their notification settings migrated.
- The Last Modified Date of a notification will reflect the migration date.
- Migrating a notification will not change its owner.
- Migrated notifications will follow the following naming convention: [notification name]_[load plan name].
Notifications of jobs taking longer than expected
You can also create email notifications for load jobs that take longer than expected, based on the load time of recent load jobs for the same load plan. This feature helps you detect delays in data refresh cycles as early as possible and act accordingly.
As this feature depends on the load plan job history, the Scheduler will skip this type of notification for load plans with no job history.
Retention of load job tracking data
With high-frequency refresh cycles, the size of load job tracking data, including load job history, load plan executions, and schema update jobs tends to increase over time, which might impact the system’s performance and the metadata database’s volume. That is why Incorta is introducing the Retention period of load job tracking data (In months) option available to the Cluster Management Console (CMC) admins to control the period for which Incorta retains load job tracking data. This option exists under Server Configurations > Tuning, and admins can set the retention period in months. The default is Never, which means that the feature is disabled.
If you enable this feature, a cleanup job runs whenever the Analytics Service starts and every 24 hours afterward and deletes tracking data that exceeds the specified retention period. However, the tracking data of the latest successful load job or schema update job will not be deleted.
Notes and recommendations
- When the cleanup job runs for the first time, it locks the metadata database during the deletion process. The locking duration depends on the number of records that the job will delete.
- It is recommended that you suspend the Scheduler before enabling the feature. Then, start the Analytics Service only and wait for a few minutes before you start the Loader Service.
- It is also recommended that you first configure the feature to start with a long retention period, then change the configuration afterward to a shorter period, and so on until you reach the required retention period. This will reduce the database lock time when the cleanup job runs for the first time.
To enable this feature, contact Incorta Support.
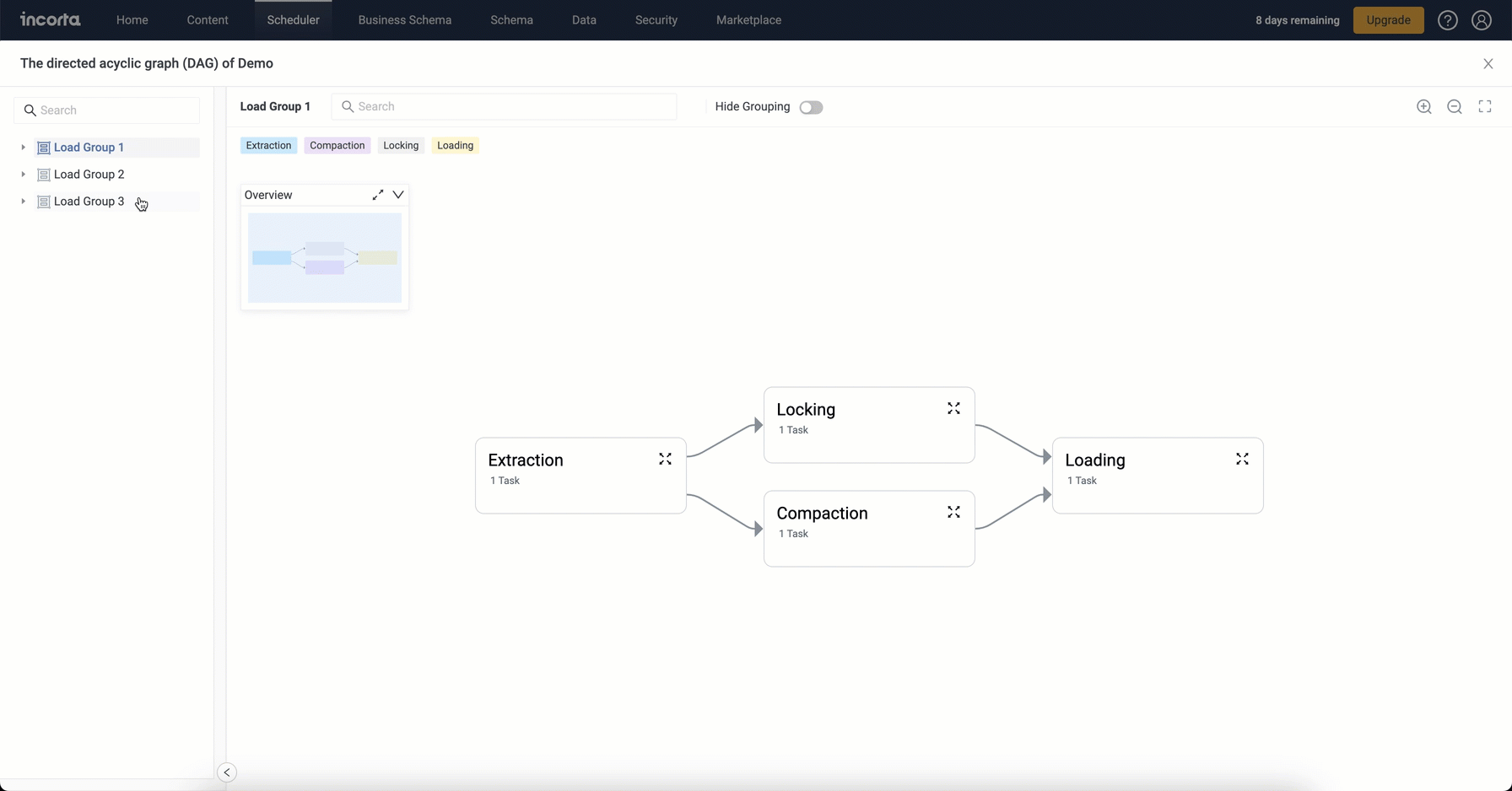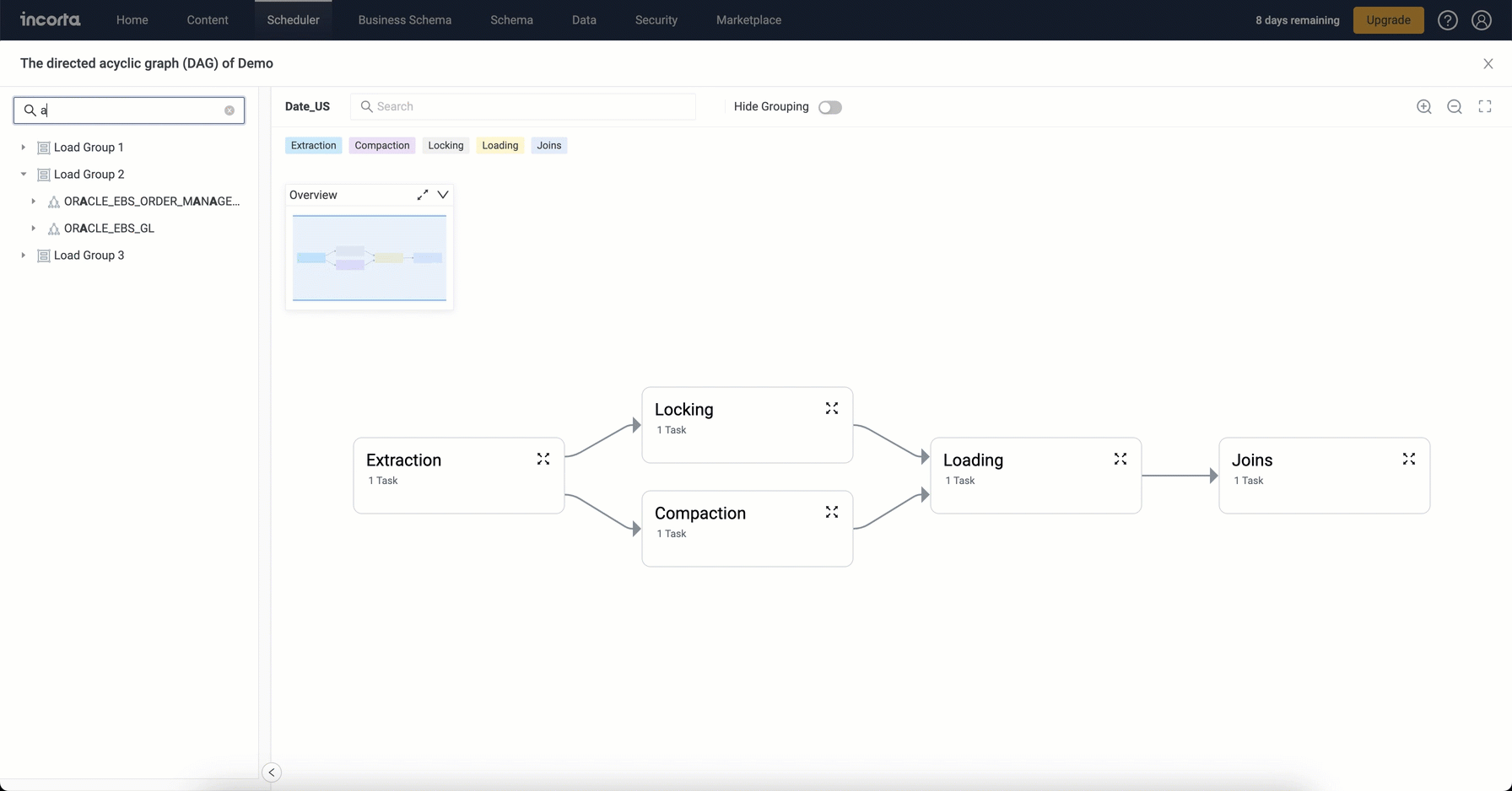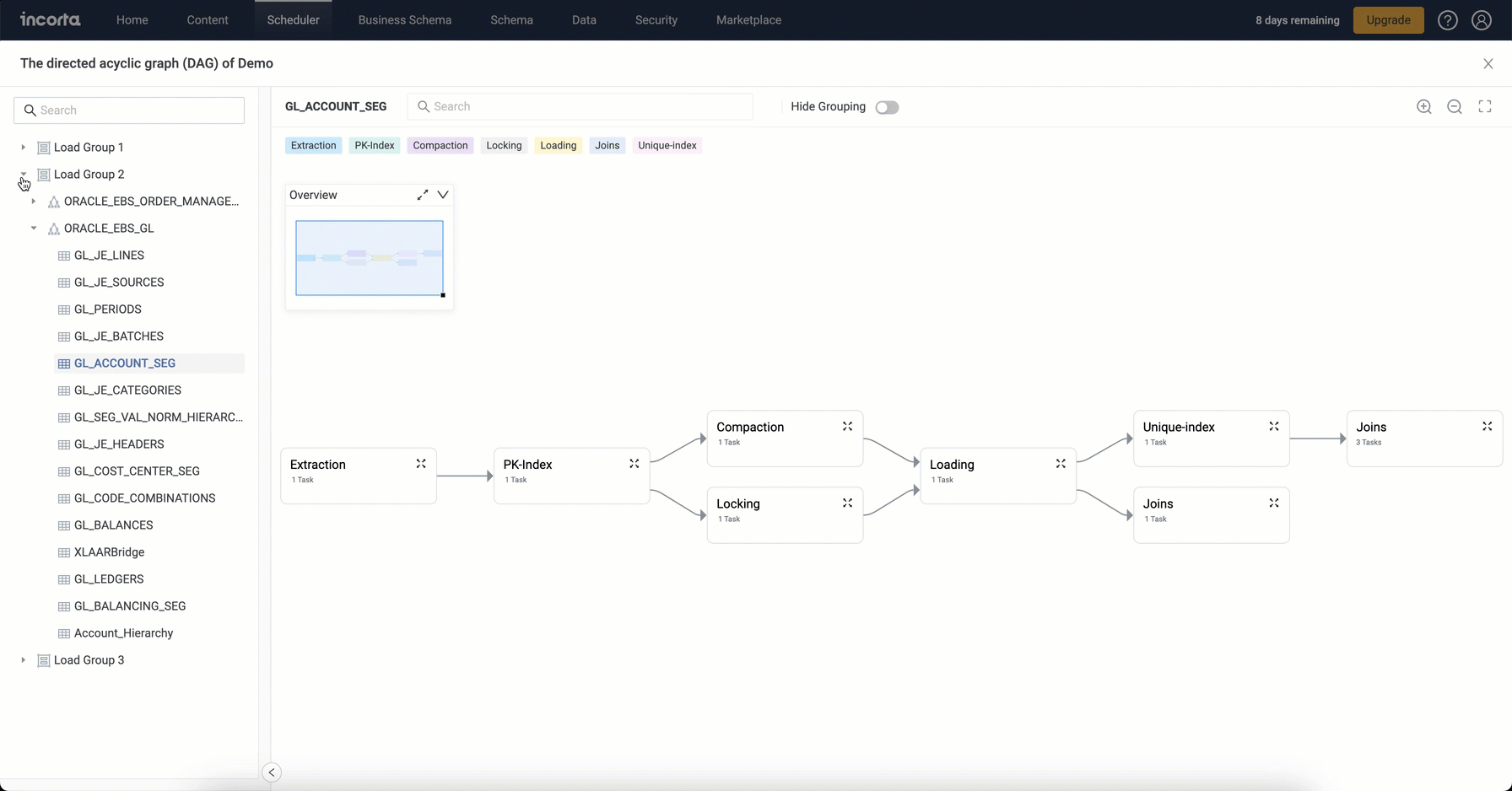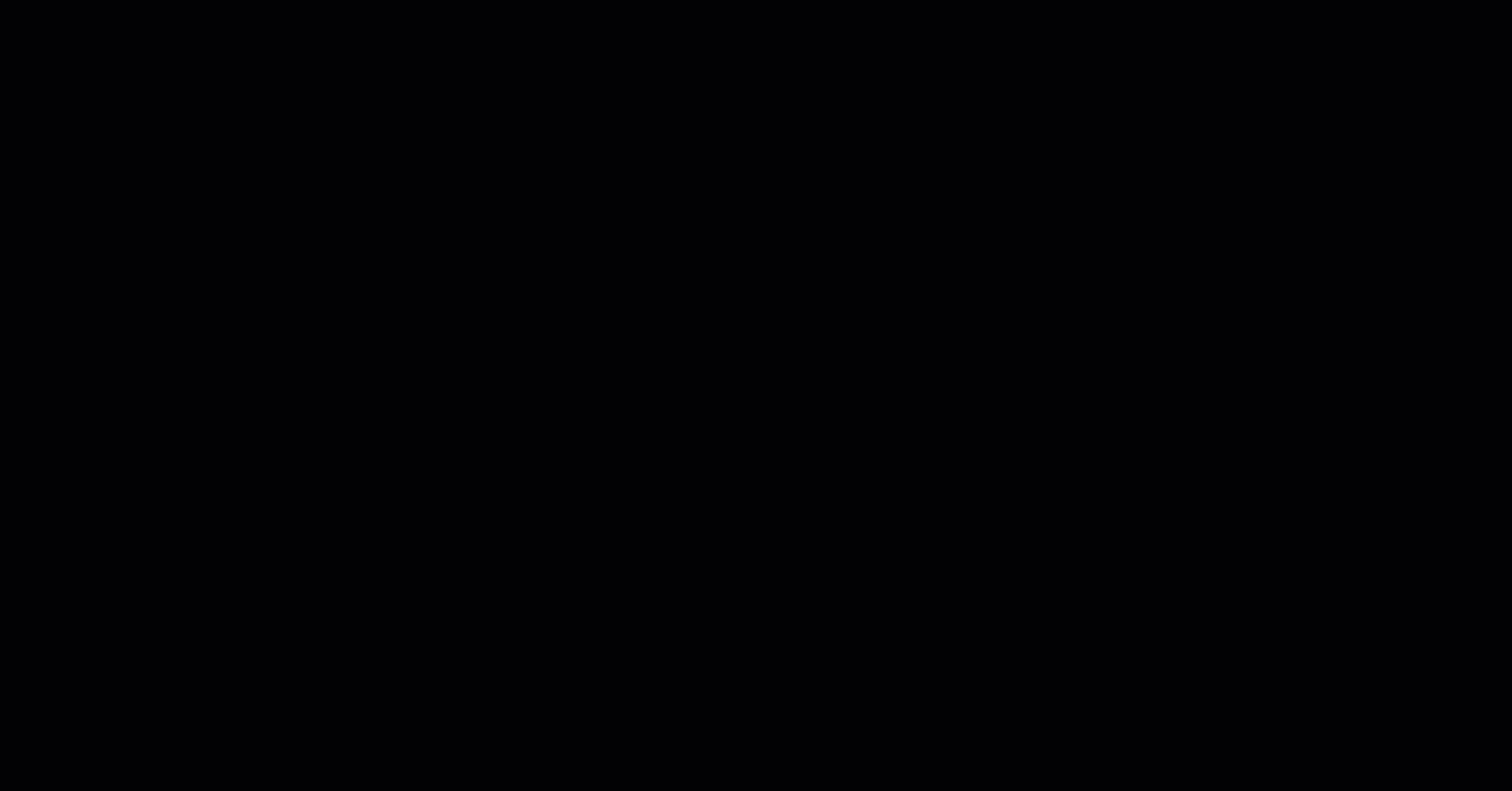
Load Plan DAG Viewer enhancements
The Load Plan DAG Viewer comes with an enhanced user experience where you can:
- Hide and show task groupings. Grouped nodes show the number of tasks included.
- Search and filter the group panel (which now shows the included schemas and their objects) by the schema or object name. Selecting a schema or object filters the diagram to show only the tasks and nodes for the selected schema or object and also filters the diagram legend to show the related task or node types only.
- Search the diagram by the object name. The search box shows matching objects categorized by task type. The search is limited to the current diagram; therefore, it is affected by the filters applied using the group panel. Selecting an object from the search list highlights the object in the respective node and also highlights it along with its upstream and downstream tasks in all expanded nodes across the diagram, showing the full path of the selected object.
Exporting and importing load plans
To facilitate migrating load plans from one environment to another or one cluster to another, you can now export and import one or more load plans, along with their scheduler details. When importing load plans, you can overwrite existing load plans that share the same name.
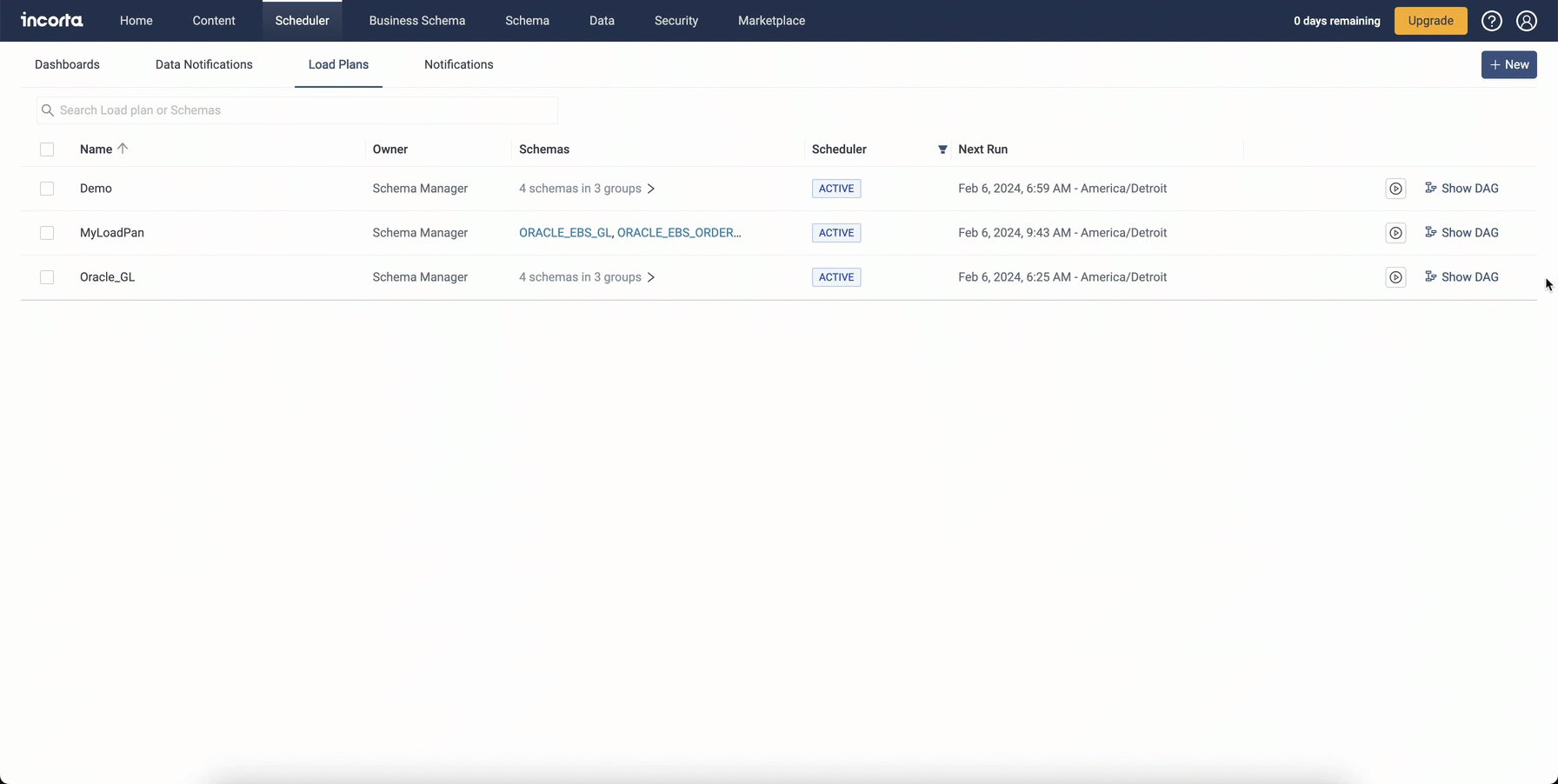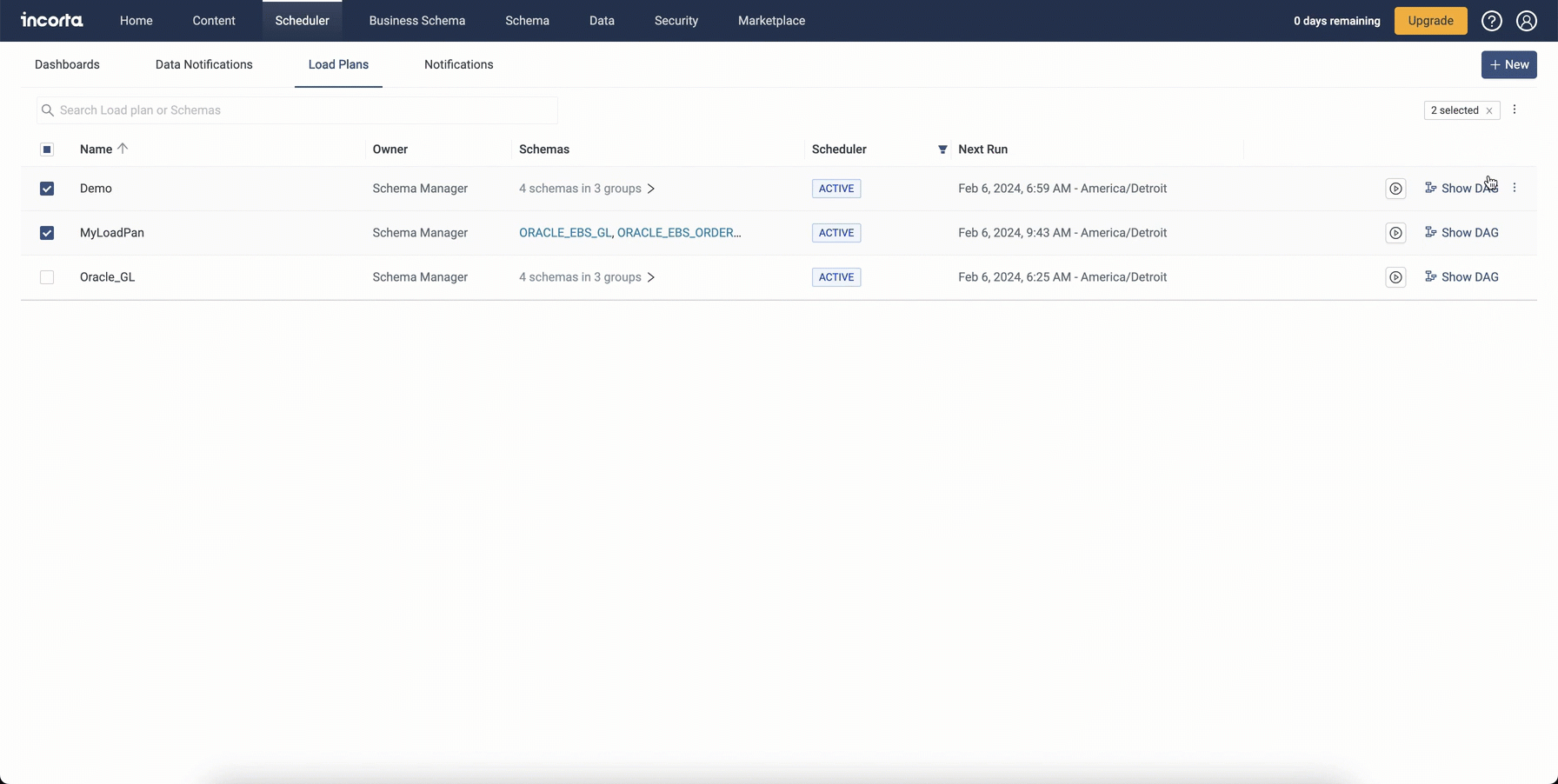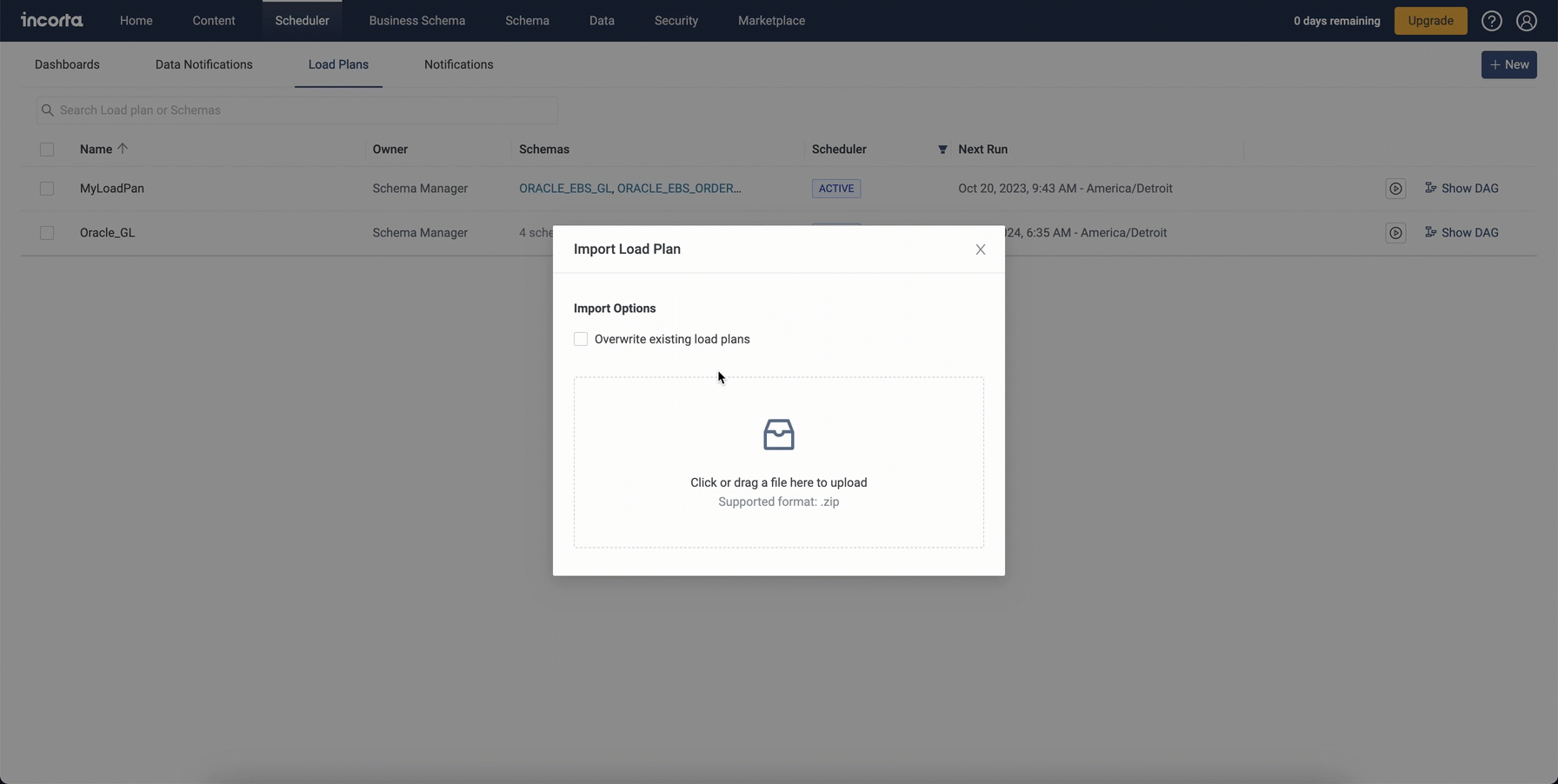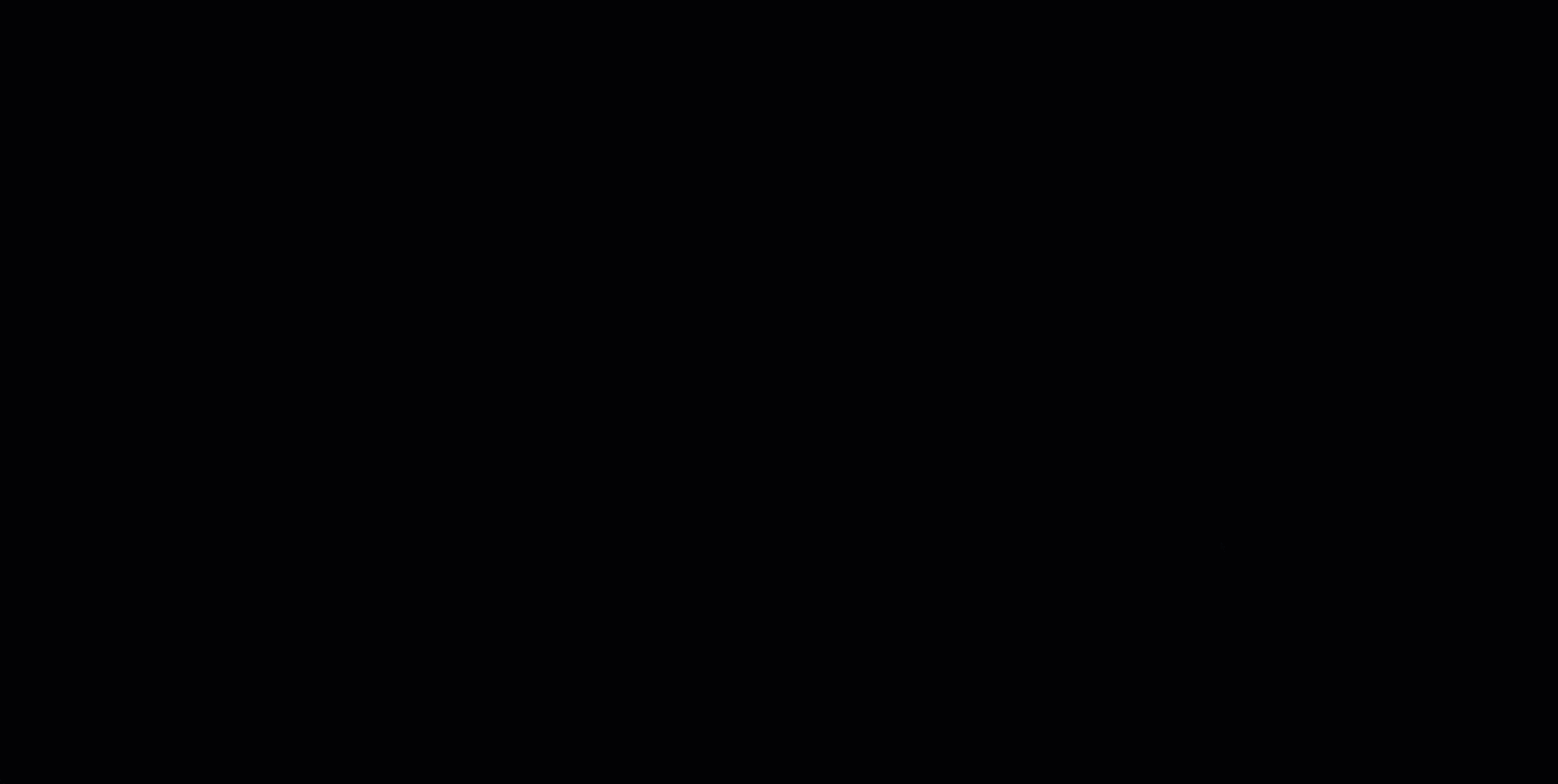
Note: Importing load plans will fail in the following cases:
- The imported load plan has one or more schemas that do not exist in the target tenant.
- You do not have edit access rights to all schemas in the load plan.
- The imported load plan shares the same name with an existing load plan while the Overwrite existing load plans option is not selected.
Support for manual load plan execution
You can now manually execute a load plan from the Scheduler > Load Plans regardless of its schedule status: Active, Suspended, Completed, or Not Scheduled. Only users who own or have Edit access to all schemas in the load plan can execute it manually. Manually executing a load plan from the Load Plans list will not impact the next scheduled run if exists.
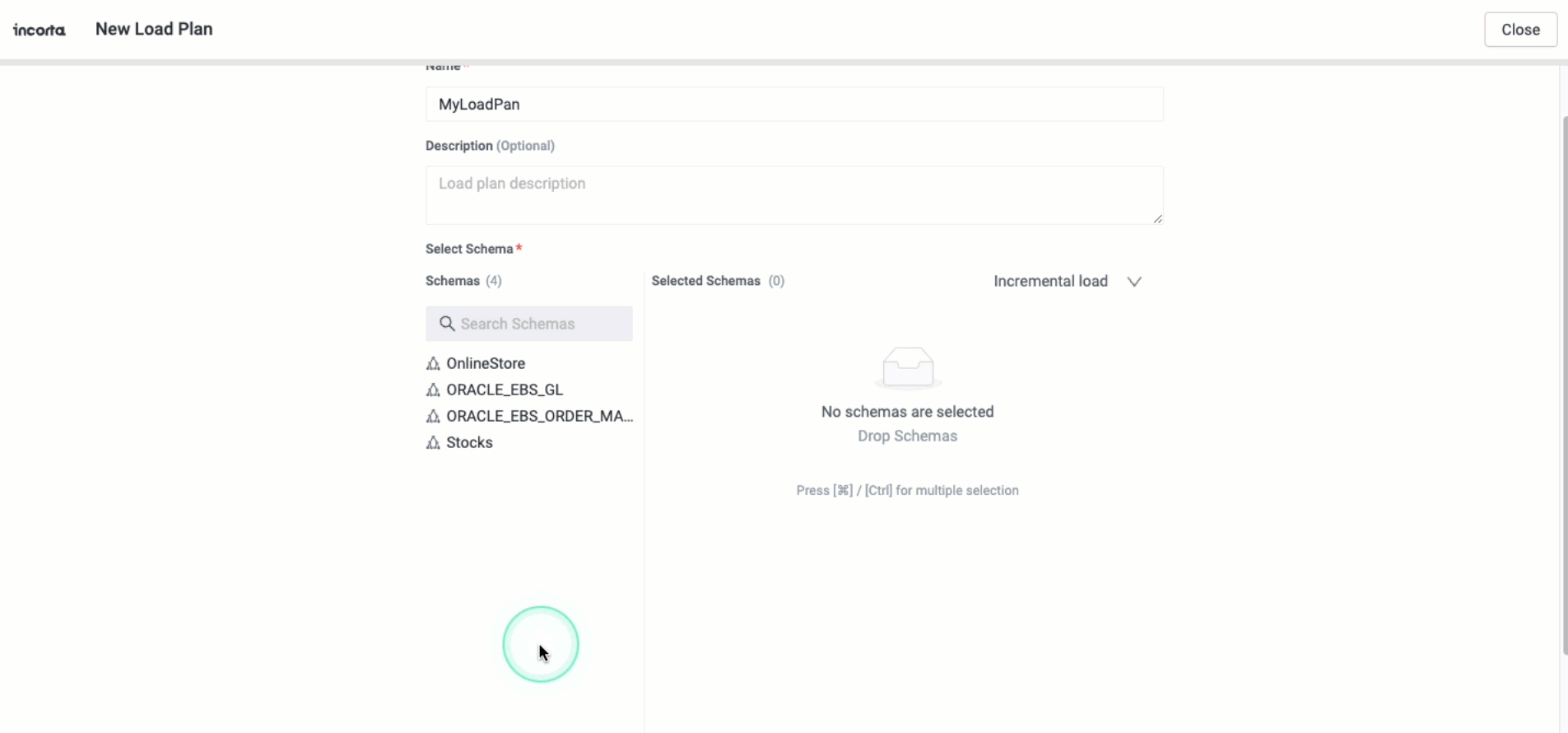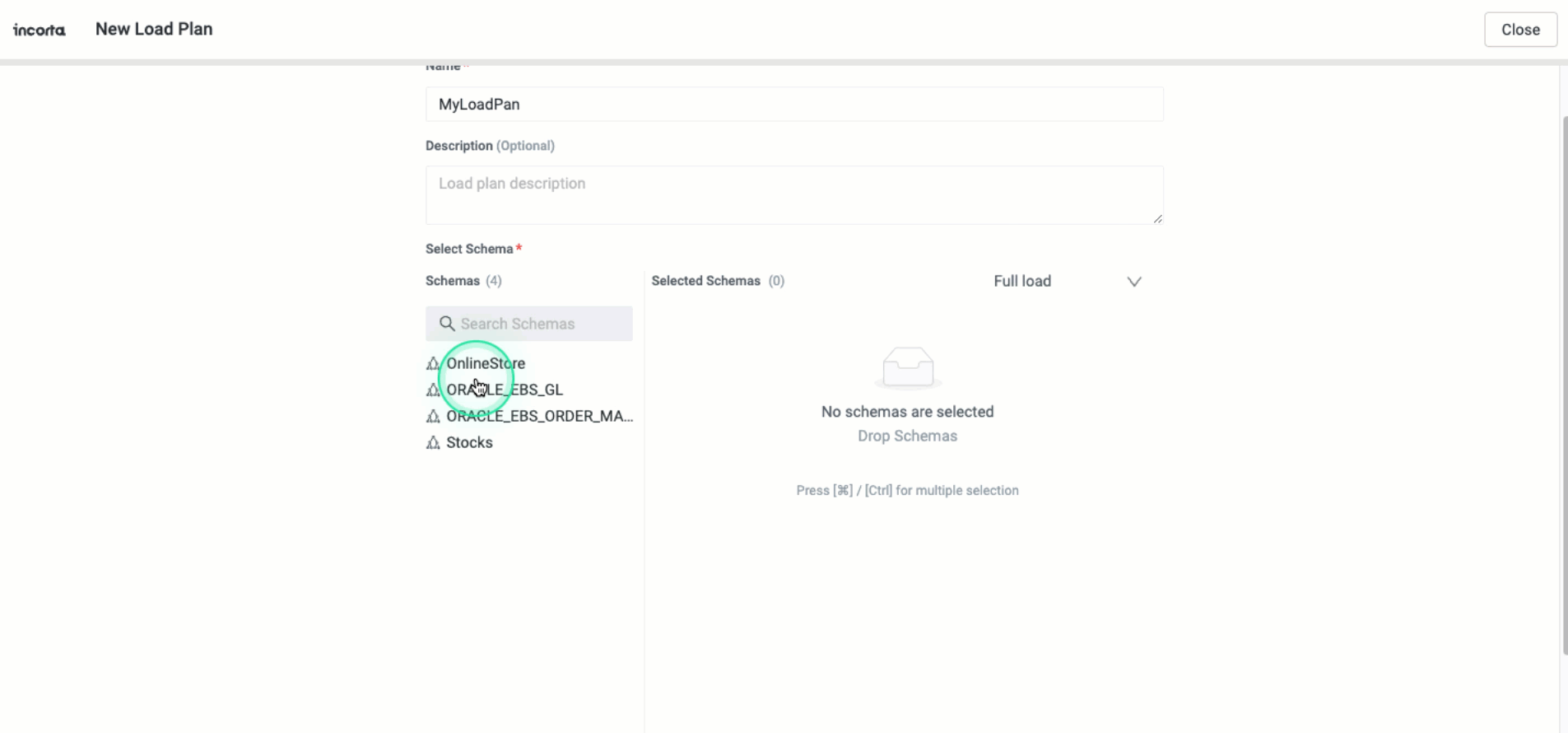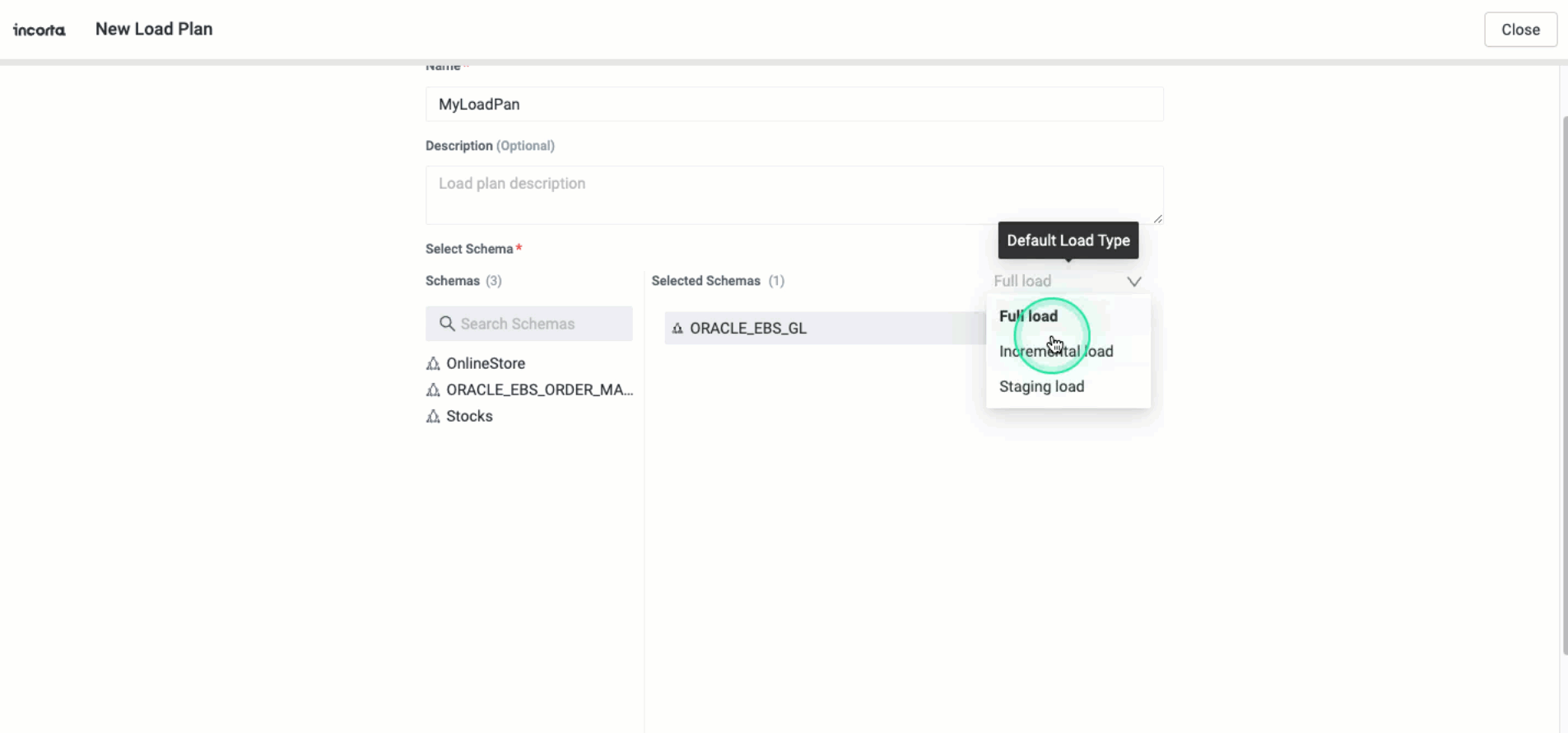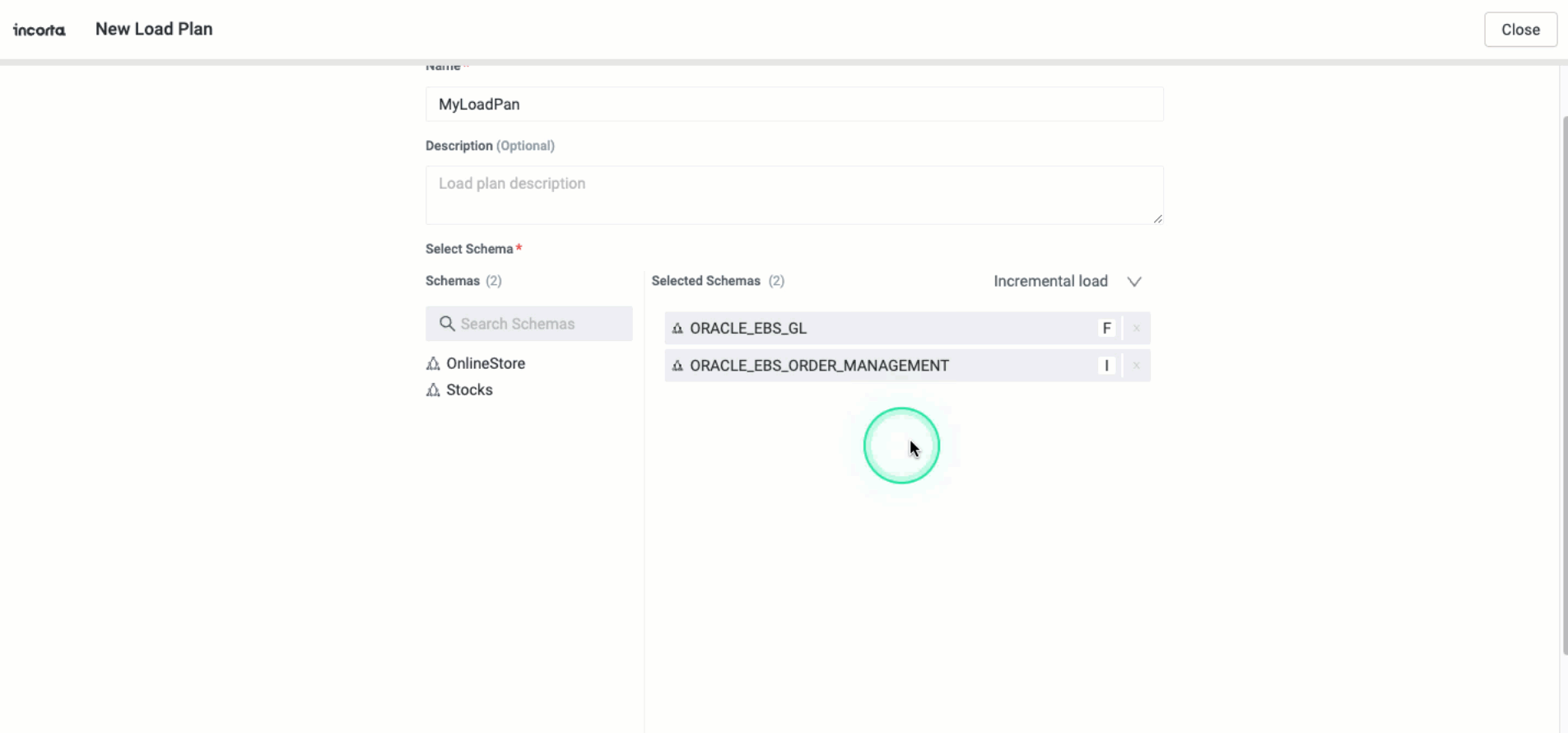
Default schema load type at the load plan level
You can now specify the default load type for schemas that you will add to a load plan. Whenever you add a new schema to the load plan, it inherits the default load type. If you change the default load type, it will not affect the schemas you have already added.
Load Job Details Viewer enhancements
- Displaying the name of the executed load plan if available.
- Displaying an indicator of the rejected rows per load group.
- Table details enhancements:
- Display the deduplication phase for tables, which tracks the duration and status of the PK-index creation and Parquet compaction processes.
- The ability to collapse and expand schema objects.
- The ability to filter by the table load status and preserve the filter during navigation where applicable.
- The ability to change the column width.
Support for merging Parquet segments during loading from staging
A new Spark job can run as part of the load from staging jobs to merge Parquet segments, which are the result of incremental load jobs. This new step increases the system resilience and enhances the performance in clusters with an increased number of small Parquet files.
To enable this feature, turn on the Enable automatic merging of parquet while loading from staging option in the CMC Server Configurations > Tuning. However, during load from staging jobs, the following conditions must be met, along with enabling the feature, to start the merging process for an object:
- The Parquet Long to Int Migration option is turned off or the object doesn’t require migrating
Longdata toInteger. - The object’s recent compacted version matches the recently extracted version, otherwise, the Loader Service performs a compaction recovery process before merging. If the recovery fails, the merge process will not start.
- The table has over 1000 eligible Parquet segments for merging.
- The estimated reduction in the number of files exceeds 50%.
Contact Incorta Support to change these configurations by editing the Loader Service’s engine.properties file and setting different values for the loader.parquet.merge.min.file.count and loader.parquet.merge.compression.ratio.threshold properties. Setting these properties to 0 or 1 means to merge whatever the file count or the gain percentage is.

Notes:
- The Parquet merge step creates a new Parquet version of the object on the disk (similar to the version created as a result of a full load job).
- The Parquet merge does not change the data merged. However, it changes the order of the records in the output Parquet files. After the merge, dashboards will show the same data, but in different order (if no sorting is applied).
Enhanced the responsiveness of Post-load interruption
This release enhances the responsiveness of interrupting load jobs during Post-load calculations. Previously, the Loader Service would wait for running calculations to complete before stopping the load job.
Pause Scheduled Jobs enhancements
Starting this release, you can choose which scheduled jobs you need to pause. Incorta replaced the "Pause Scheduled Jobs" toggle in the CMC with three toggles to give you more flexibility on which scheduler jobs you want to pause.
In the CMC > Clusters > cluster-name > Cluster Configurations > Default Tenant Configurations > Data Management (known as Data Loading in previous releases), you can find the three new toggles:
- Pause Load Plans
- Pause Scheduled Dashboards
- Pause Data Notifications

These options are disabled by default, enabling them will display a message in the Analytics to indicate that this service is disabled.
For more information refer to Guides → Configure Tenant.
Incorta has also applied the same change while importing tenants. During the import process, you can choose which scheduled jobs you need to pause for the tenant you are importing.

For more information refer to Tools → CMC Tenant Manager.
Support OAuth for JDBC connection
Incorta now supports OAuth for JDBC connections. You can enable this option from the CMC. Log into the CMC and Navigate to Clusters > cluster-name > Cluster Configurations > Default Tenant Configurations > Integration. Enable the option OAuth 2.0-based authentication for JDBC connection, knowing that by enabling this option you cannot use personal access tokens for JDBC authentication.
Enabling this option will show the field OAuth 2.0 authorization server base URL, where you can type in your authorization server URL. Any URL change requires restarting the Analytics service to take effect.

Monitoring the file system usage
This release introduces a new feature to monitor how Incorta services use the file system and to collect the file system metrics. For now, this feature supports Google Cloud Storage (GCS) only.
This feature is disabled by default. Contact Incorta Support to enable the feature for each service that you want to monitor its requests (method calls) and set the interval to log the file system metrics in the service log file and the newly introduced file system audit file. Additionally, the feature can be configured to log detailed metrics in the tenant log file; however, it is not recommended to always enable this property as it might cause performance degradation.
Enabling or disabling this feature does not require restarting the respective service; however, updating any other property, including changing the time interval or enabling or disabling the detailed metrics logging, requires restarting the related service.
Enhanced performance with parallel snapshot reading
Now, Incorta can read the snapshot DMM files of joins and formula columns in parallel using multiple threads to enhance and speed up reading these files. The performance enhancement may vary according to the number of columns and joins to read concurrently and the available resources.
This feature is disabled by default. To enable it, contact Incorta Support.
Advanced SQL Interface
In this release, Incorta is introducing a new advanced SQLi that is fully Spark SQL compliant. With this compliance, the new SQLi introduces a new enhanced performance and compatibility with more external tools. You can also use the advanced SQLi with Incorta using the Kyuubi connector.
Advanced SQL Interface is a preview feature.
The Advanced SQL interface is disabled by default. To enable it, you must log into your Cloud Admin Portal (CAP) and turn on the Enable Advanced SQL Interface toggle the Configurations tab.
When enabled, the connection string is generated for you to use in your third-party tools or Incorta via the Kyuubi connector.

When enabling and working with the advanced SQLi, you must be aware of the following:
- Enabling the advanced SQLi will automatically enable the Null Handling feature, regardless of any previous configurations.
- Incorta will restart both Analytics and Loader services.
- The username is always written in the format:
<username>%<tenant-name> - To authenticate Incorta, you must generate a personal access token (PAT) to use as a password while connecting to the advanced SQLi.
- If you want to use OAuth 2.0 for authentication instead of PAT, you must enable OAuth 2.0-based authentication for JDBC connection from the CMC under Default Tenant Configurations > Integrations.
- Advanced SQLi retrieves verified Views only. When you try querying a non-verified view, SQLi will result in a "not found" error.
- Using the advanced SQLi requires data to be synched with the Spark Metastore.
Known limitations
- Only a single analytics service is supported.
- Geo data type is not supported.
- Spark Metastore does not support synchronizing SQL views, non-optimized tables (partially supported in 2024.1.3), and Analyzer views.
- Only one schema is synchronized in case multiple exist with the same name, regardless of case sensitivity.
Additional Considerations
In case of using a tenant with the same name as a previously deleted one, please contact Incorta Support so you can avoid facing issues while using the Advanced SQL Interface. This issue has been resolved starting 2024.1.3 Maintenance Pack.
For more information, refer to References → Advanced SQL Interface.
Maintenance Packs
2024.1.1 maintenance pack
Incorta copilot for story telling
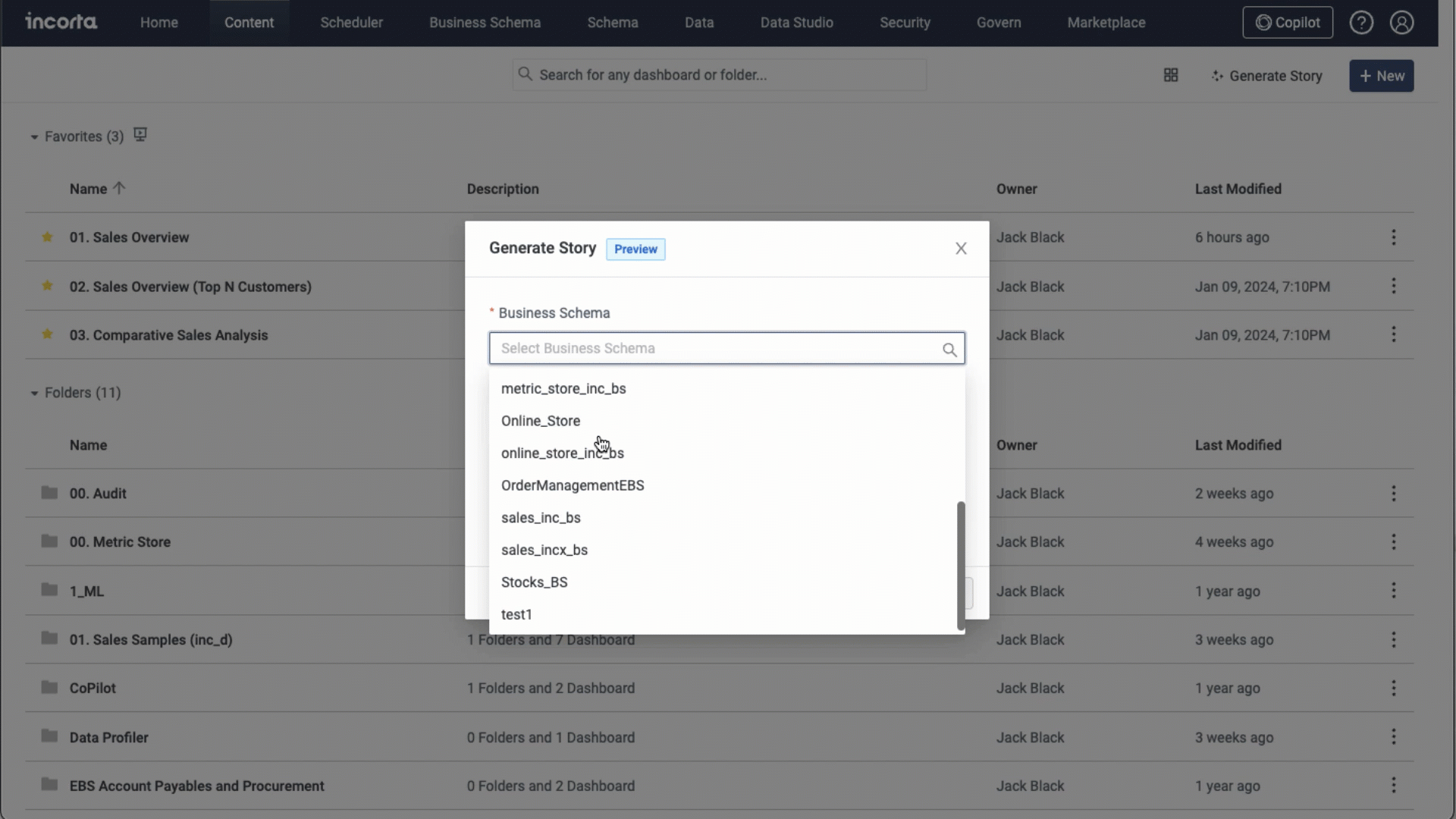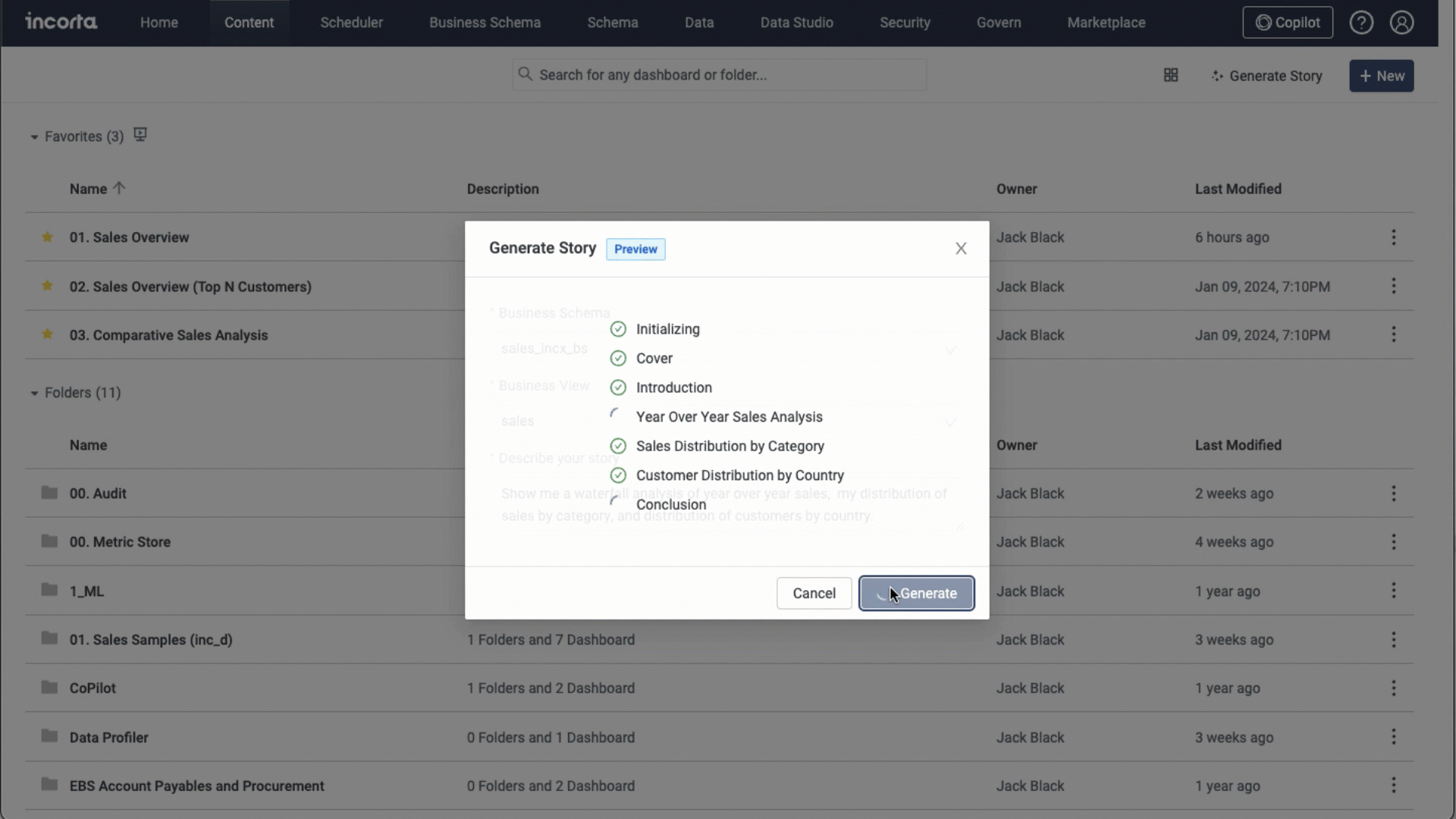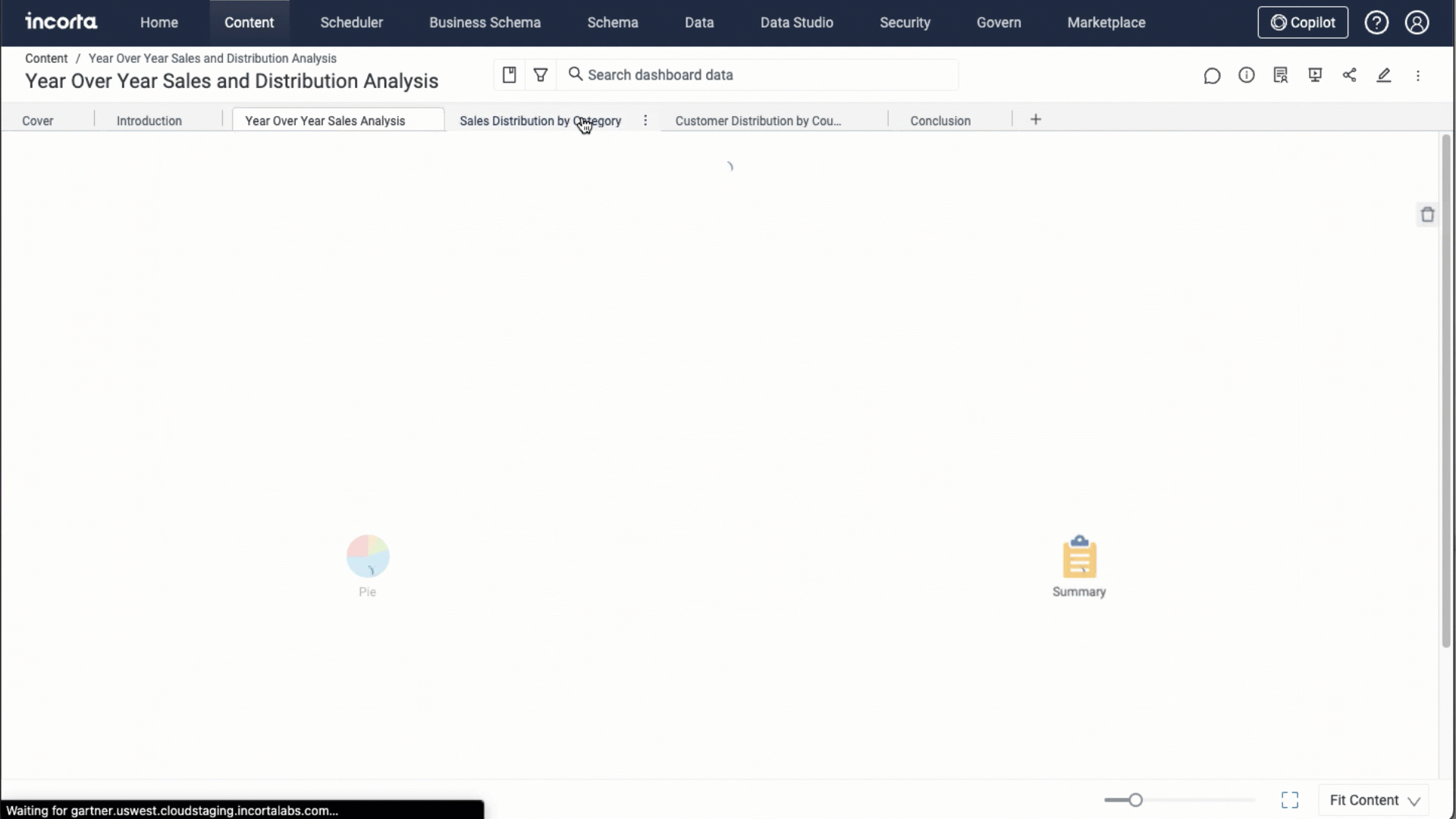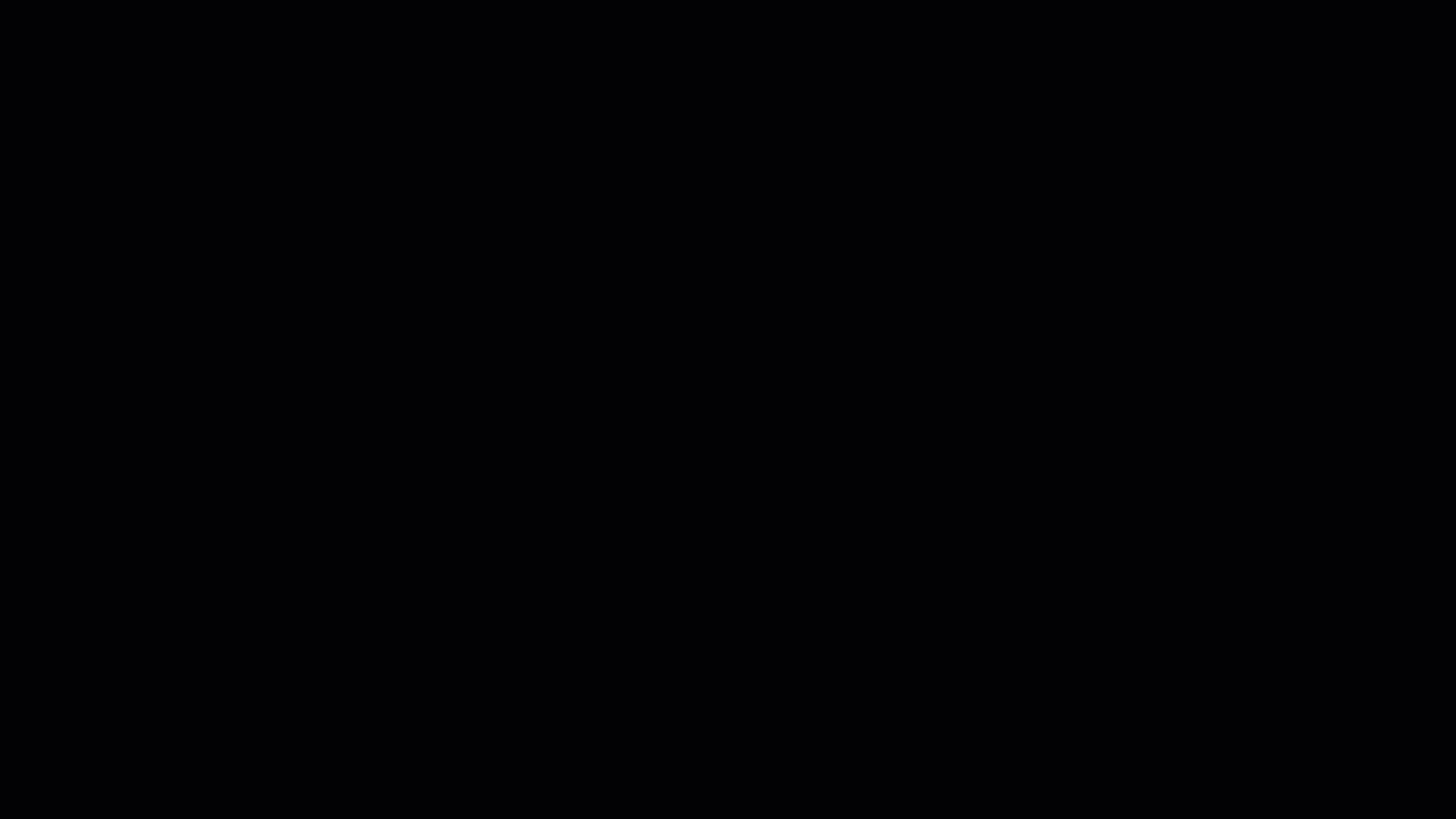
With this feature, Incorta enhances the capabilities of dashboard developers, enabling them to construct an entire dashboard using natural language. You can find a new Generate Story button in the Action bar within the Content Manager.
The Incorta Copilot for storytelling is currently in preview and is accessible only if you have configured the Incorta Copilot.
The Incorta Copilot for storytelling feature exclusively relies on verified business views.
When you select the Generate Story button in Incorta, a dialog box will appear. This box will ask you to specify the business schema and business view that you want to use for your dashboard. Additionally, you need to provide a brief question or desired report outline to generate your dashboard.
Incorta generates the dashboard consisting of 6 tabs, which includes: Cover, Introduction, Conclusion, and other 3 variant tabs.
Currently, the story telling feature only supports the following visualizations: Bubble, Spider, Waterfall, Word Cloud, Line, Sankey, Scatter, Waterfall, Column, Pie, and Donut visualizations and their variations.
Send a single insight
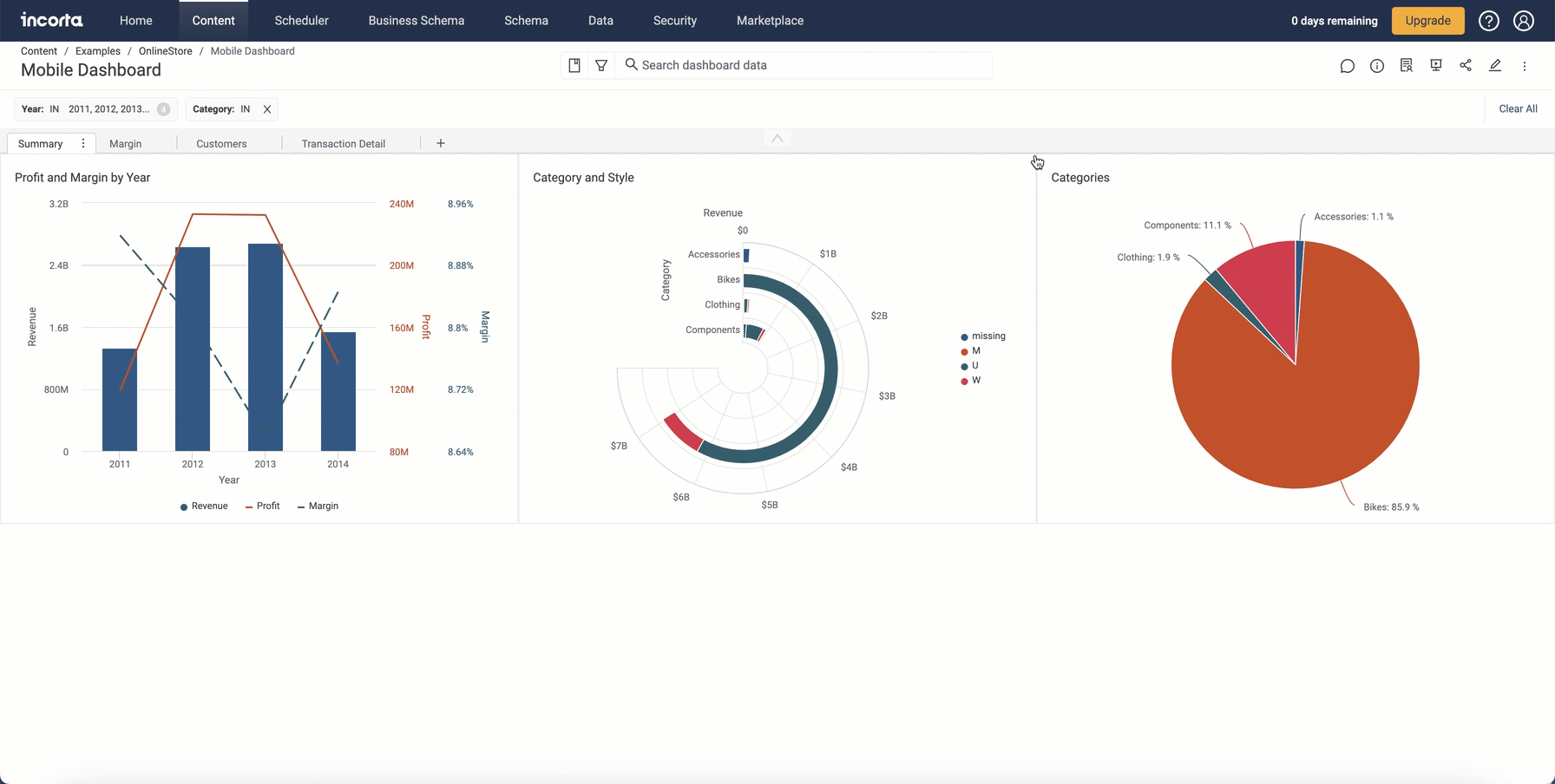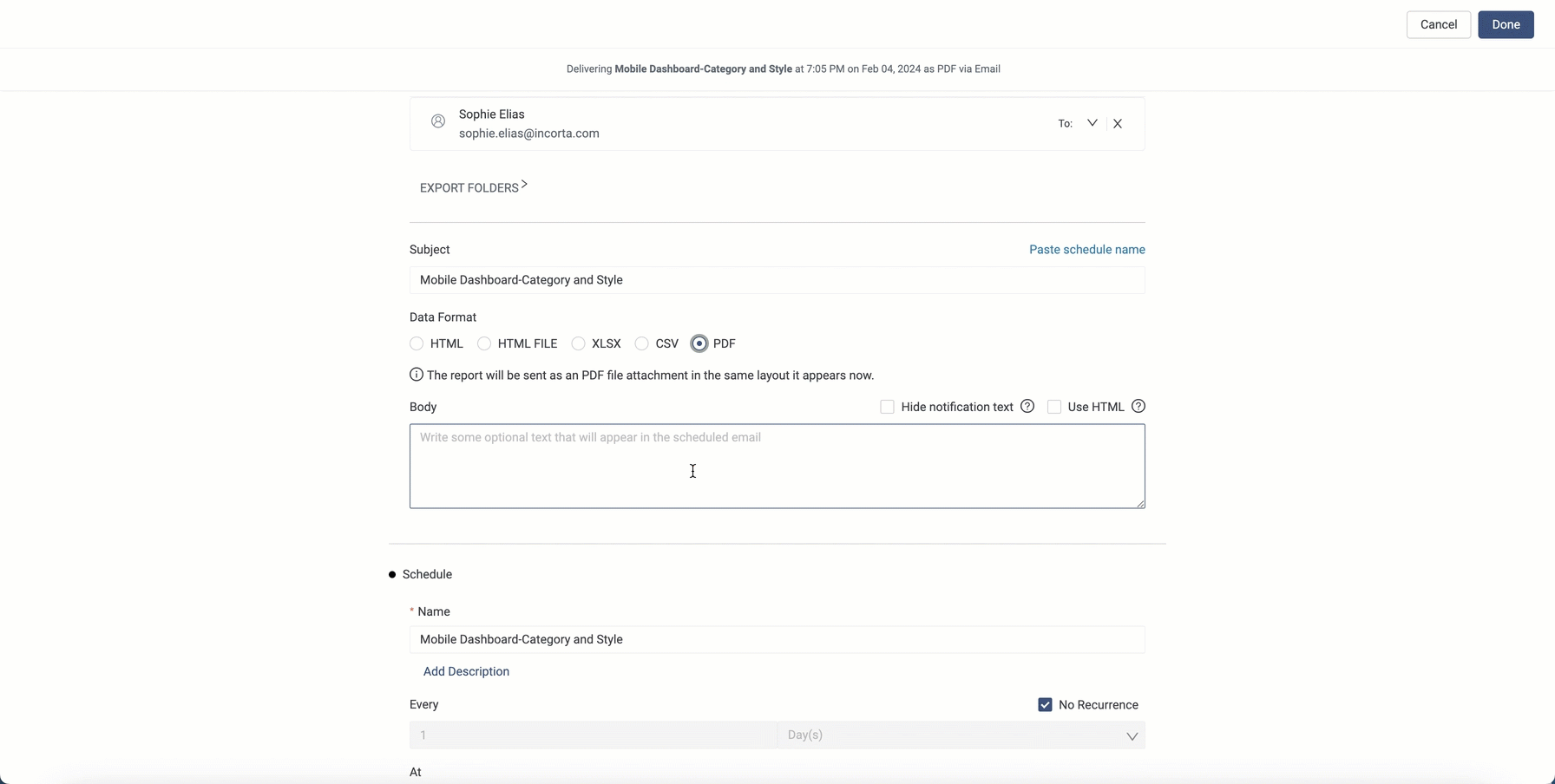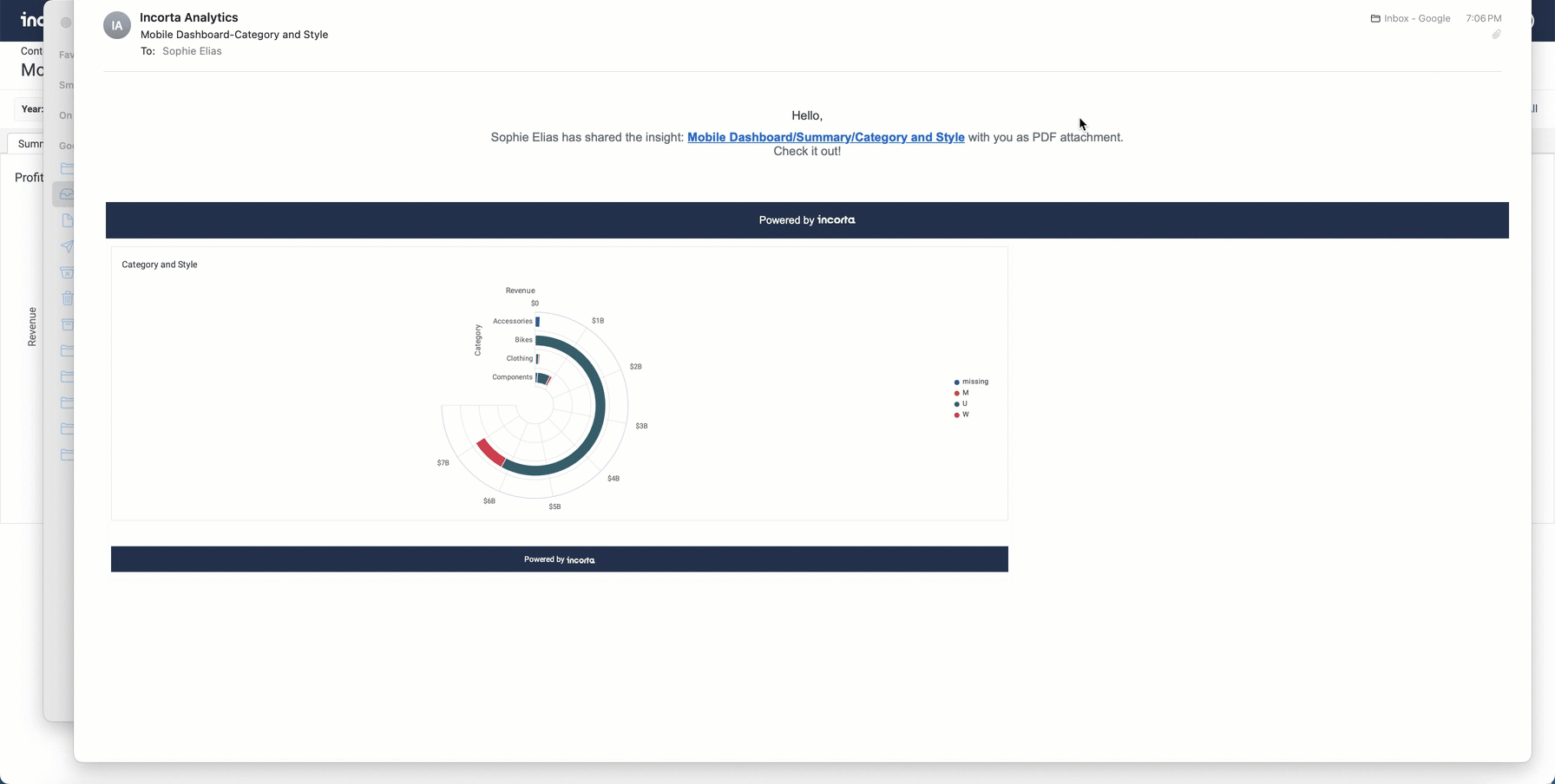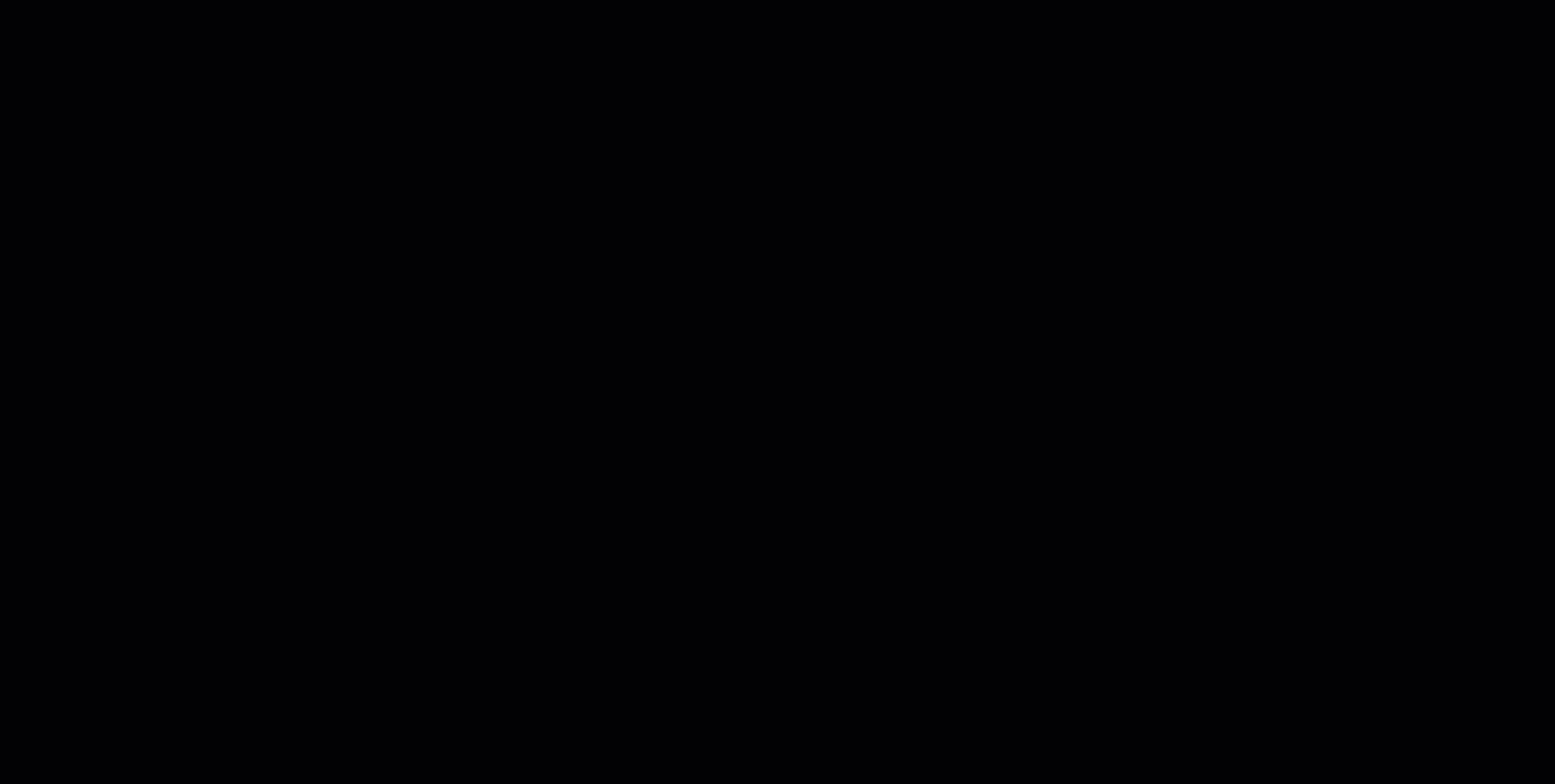
You can now schedule the sending of a single insight from a dashboard without the need to send the entire dashboard, utilizing the Send/Schedule a Report option. This feature is introduced to facilitate the sending of tabular insights that include pagination.
You can access this capability in the More Options menu of an insight, replacing the previous Send to Data Destination option. Upon choosing the Send/Schedule a Report option, Incorta opens the Scheduler, allowing you to configure the delivery of the insight.
When sending a tabular insight with multiple pages, it is recommended to send it in XLSX format.
2024.1.2 Maintenance Pack
Derived tables’ support for key columns
Now, you can specify key columns for Incorta Analyzer and SQL tables. Adding, removing, or changing key columns does not require running a load job, as derived tables are refreshed as part of schema update jobs. The derived table’s unique index is calculated and saved as a snapshot DDM file each time the key columns are updated or the schema or table is loaded.
Ensure that the column or columns you designate as key maintain row uniqueness because no deduplication is performed for derived tables. If the selected key columns result in duplicate key values:
- During the schema update job, duplicate values are kept, and the Engine will return the first matching value whenever a single value of the key columns is required. The schema update logs will point out the unique index issue.
- During the schema or table load job, the unique index calculation will fail, resulting in a finished-with-error load job. No value is returned when the unique index is required. You must select the correct key columns to have the unique index calculated.
2024.1.3 Maintenance Pack
What's new
- Relaxing the lookup function validation
- Multiple default groups by dimensions in aggregated table
- Dynamic Pivot Table Analysis
- Wrap the Label Text in the Dual X-axis chart
- Export Current Dashboard State
- Improved Handling of Cyclic Dependencies in Variables
- Querying non-optimized tables via Advanced SQL Interface
Relaxing the lookup function validation
The validation on the lookup() function introduced in 2024.1.0 is now relaxed to allow:
- Using columns from business schema views with columns from the source physical schema object in the same expression
- Limiting the validation to creating new or updating existing expressions
- Existing expressions where the
result lookup fieldandprimary key fieldparameters are not from the same object or its business schema views not to return an#Errorvalue
Multiple default groups by dimensions in aggregated table
The dynamic group-by is a powerful feature in Incorta's aggregated tables. In the latest update, users can override the default grouping behavior in which the first dimension in the grouping dimension tray is displayed. Instead, users can select which grouping dimension(s) to show as a default for dashboard consumers.
Dynamic Pivot Table Analysis
In this release, pivot tables have added two powerful enhancements:
- The ability to define a dynamic group by logic (previously only available in aggregated tables)
- The ability to define dynamic columns
As a result, users can interactively select and de-select rows and columns to display in their pivot table. As a bonus, these two new features also allow users to set a default view.
Wrap the Label Text in the Dual X-axis chart
There is now a new lab format option to wrap the text label for the Dual X-axis chart. This format option applies to the upper X-axis. You can keep the original behavior, where the text exceeding the reserved area of the label is trimmed, or toggle label wrapping in the pill settings.
Export Current Dashboard State
Incorta can now export dashboards for PDF and HTML in their current view state in this release instead of reverting to their default state. The following actions supported from an end-user interaction that can be exported are:
- Sorting
- Dynamic Group By (in tables)
- Dynamic Measures (in tables)
- Dynamic Fields (used in measures)
If a dashboard consumer has used the above actions before exporting, the exported in a direct or scheduled dashboard export will reflect their changes. When exporting the dashboard, under the Choose Bookmark option, you can select existing bookmarks or “Current Dashboard State”. Note that dashboard states have the option to save to bookmarks.
Improved Handling of Cyclic Dependencies in Variables
This enhancement focuses on improving system resilience and stability by resolving issues related to infinite loops and overflow exceptions caused by cyclic dependencies in variables. However, it's essential to acknowledge that a standardized error message or expected output has not yet been established. Users may encounter varied outputs, including #Error, 0 rows, empty strings, or variable name displays, depending on the context. Ongoing efforts are dedicated to achieving uniform error handling and output consistency.
Querying non-optimized tables via Advanced SQL Interface
Non-optimized tables can now be accessible via the Advanced SQL Interface. As a result, external tools, such as Tableau and Power BI, can now discover and query non-optimized tables that do not have any of the following:
- Security filters
- Formula columns
- Encrypted columns
Contact Incorta Support to help you configure your cluster.